Note: phiên bản Tiếng Việt của bài này ở link dưới.
https://duongnt.com/sqs-services-integration-two-vie
![]()
In a previous article, we took a look at Amazon SQS and see how we can interact with it using C#. Today, we will explore a hypothetical scenario and see how a SQS-based messaging solution can help us integrate multiple services.
Note that Amazon SQS has a limit of 256KB per message, but let’s say packages in our system are smaller than that.
Our scenario
Tale of a social network
Our company, called Beyond, has developed a social network called Headtome using C#. Headtome allows its users to upload their statuses and pictures then share them with the world. Just like any social network worth its salt, Headtome performs data analysis on all those pictures, this is done by an independent service. Also, for disaster recovery purposes, we archive all pictures at a secured site in compressed form.
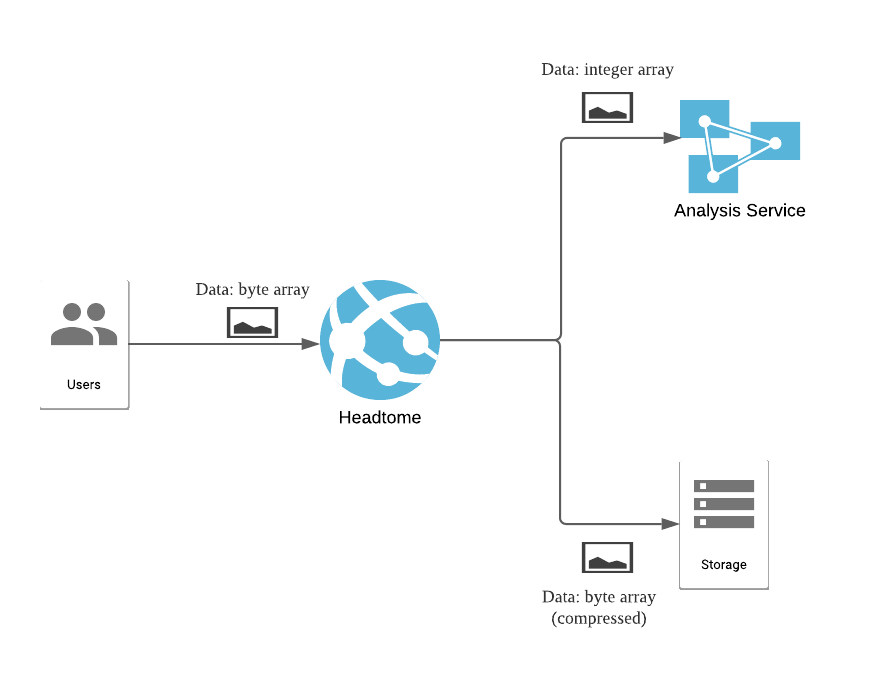
All services use JSON to pass data, but each one requires pictures to be in a different format. Users uploaded their pictures, which use the RGB model, as uncompressed byte arrays. This is also the format used inside Headtome.
{
"id": "<picture UUID>",
"user_id": "<user UUID>",
"data": "64756f6e67..."
}
On the other hand, the analysis service can only receive data as a one-dimensional integer array. Because the original pictures use the RGB model, we need to read the values in each color channel, then flatten them.
{
"id": "picture UUID",
"user_id": "<user UUID>",
"data": [17, 10, 27, 10,...]
}
And the storage service receives data as compressed byte arrays.
{
"id": "<picture UUID>",
"user_id": "<user UUID>",
"data": "6c7579..."
}
An acquisition
Headtome was a huge success. Thanks to it, we have the fund to acquire a photo and video sharing service called Rapidpound. We want to integrate all pictures collected via Rapidpound into the same workflow that Headtome is using, but there are some obstacles. It turns out that Rapidpound was written in Python, and stores pictures using the HSV model.
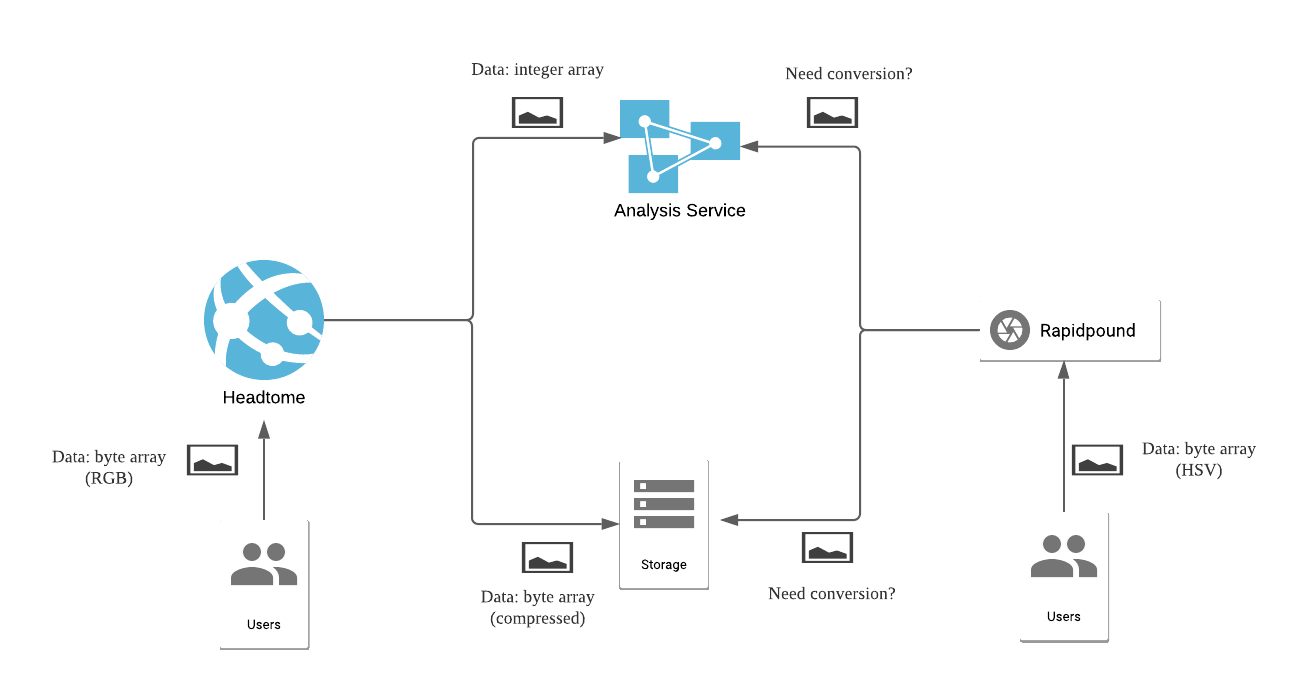
One might think that we can simply add new code to Rapidpound and convert all pictures to the correct format before forwarding them to other services. But the more code we add, the more code we will need to test, maintain, and undoubtedly debug in the future. Not to mention that we will burden Rapidpound with responsibilities that it shouldn’t have to care about. Also, in the future, we might want to integrate Rapidpound with even more services written in other languages. Do we really want to change its source code every single time?
From Headtome‘s side, things are not perfect either. We are coupling it to the analysis service and the storage service. What if other services need Headtome data? What if we want to send data from Headtome to a different service?
Messaging-based integration
Below are the biggest issues we are facing.
- It’s difficult to keep track of which services are sending data to which services. And it’s even harder to change this dynamically.
- Different services require data in different formats. The conversion between each format is not complicated by itself, but making sure the right conversion is used at the right time certainly is.
- If we are not careful, a service can overload another one.
- When a service is down, all data sent to it will be lost.
We will try to solve all of them with messaging-based integration using Amazon SQS.
Introducing an integrator service
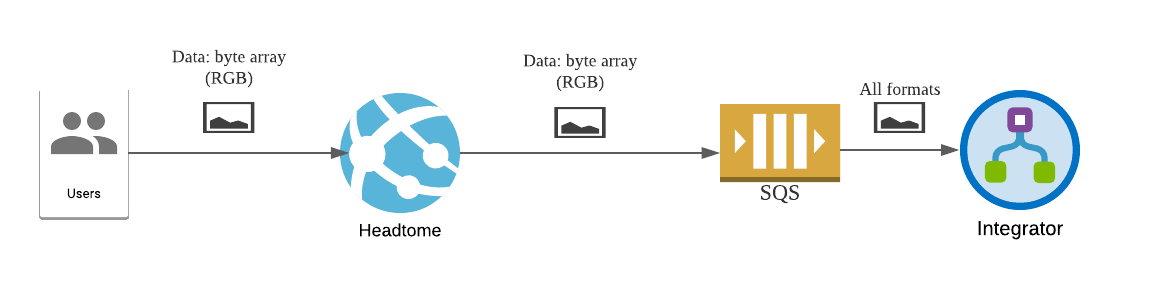
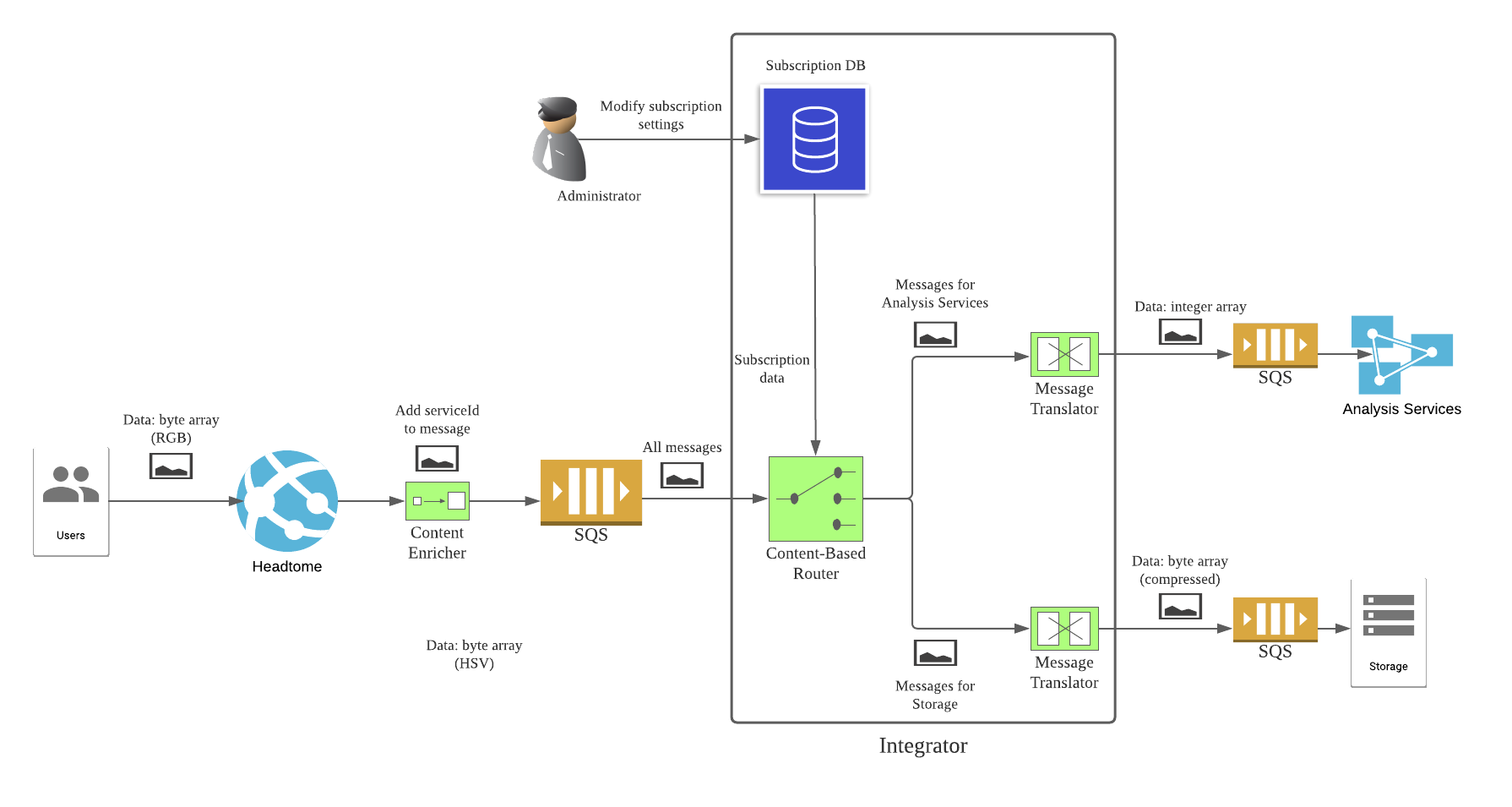
Fortunately, we have prepared for this day right from the start. Headtome actually does not send data directly to the analysis service and the storage service. It considers each picture and its metadata as a message, and sends all messages to a SQS queue. Then the integrator will retrieve messages from that queue, convert it to the correct format, forward it to the correct endpoint(s), then delete the processed message. The integrator can decide how fast or slow it processes messages from the queue. If there is a burst of messages, some of them might be delayed, but eventually the integrator should catch up.
To differentiate messages from different services, we add a Content Enricher before the SQS queue. This module will attach a serviceId to each message. For example, a message from Headtome looks like this.
{
"id": "<picture UUID>",
"service_id": "<Headtome's serviceId>",
"user_id": "<user UUID>",
"data": "64756f6e67..."
}
The integrator will use this serviceId to decide to send a message to which endpoint. Notice that a message can be forwarded to more than one endpoint. In our case, both the analysis service and the storage service have subscribed to receive messages from Headtome.
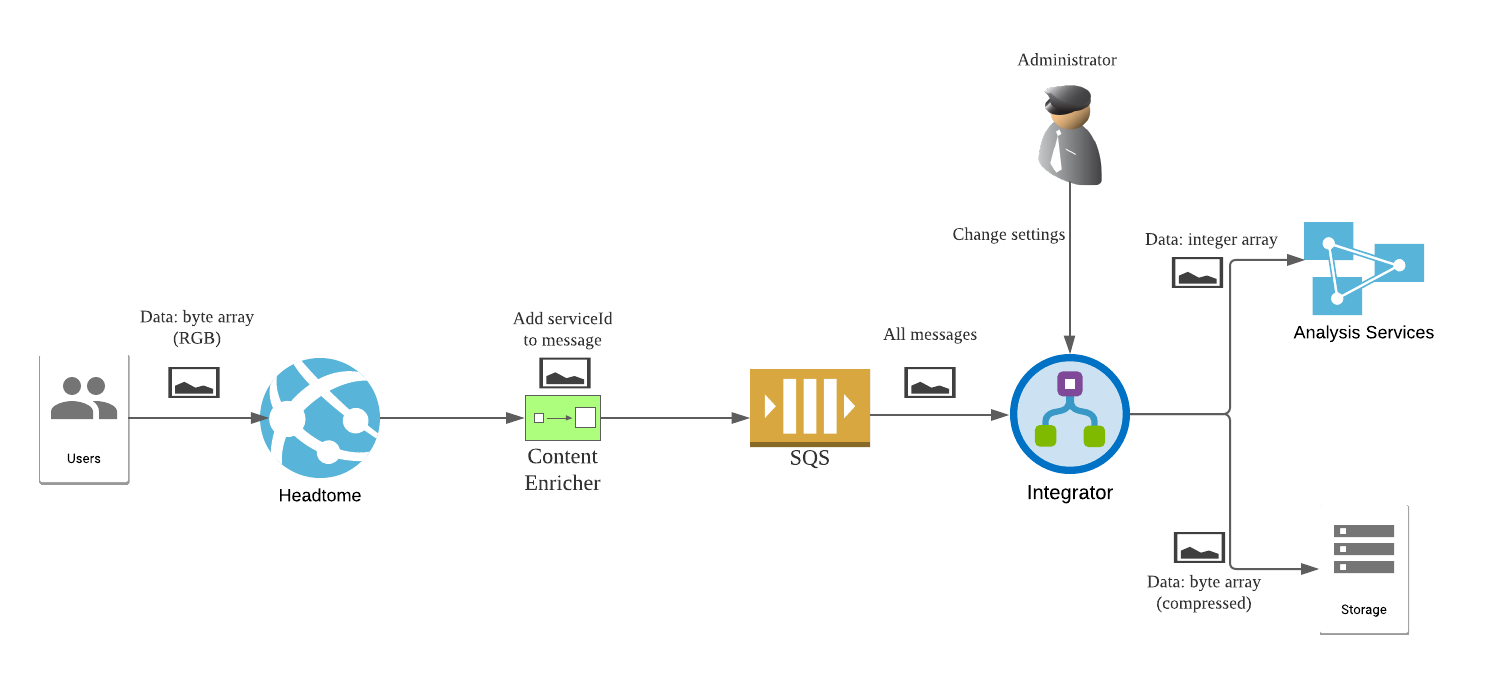
The integrator consists of a subscription database, a Content-Based Router, and multiple Message Translator. The Content-Based Router reads the serviceId from each message, and combines it with the subscription data from the database to determine the destination. The messages are then sent to the suitable translator(s), where they are converted to the correct format. After that, we can forward the converted messages directly to endpoints. But to make our system more scalable, messages are sent to services’ own queues instead. Each service can then control the rate to pull messages from its queue.
Handle messages in the wrong format
In a perfect world, all messages we receive can be converted into a suitable format. But what if we receive a bad message? Obviously, the Message Translator is the best place to handle such errors. Whenever it encounters a bad message, the translator will store the message’s content into a database. Then we can provide a Web UI to display those invalid messages for diagnostic purposes.
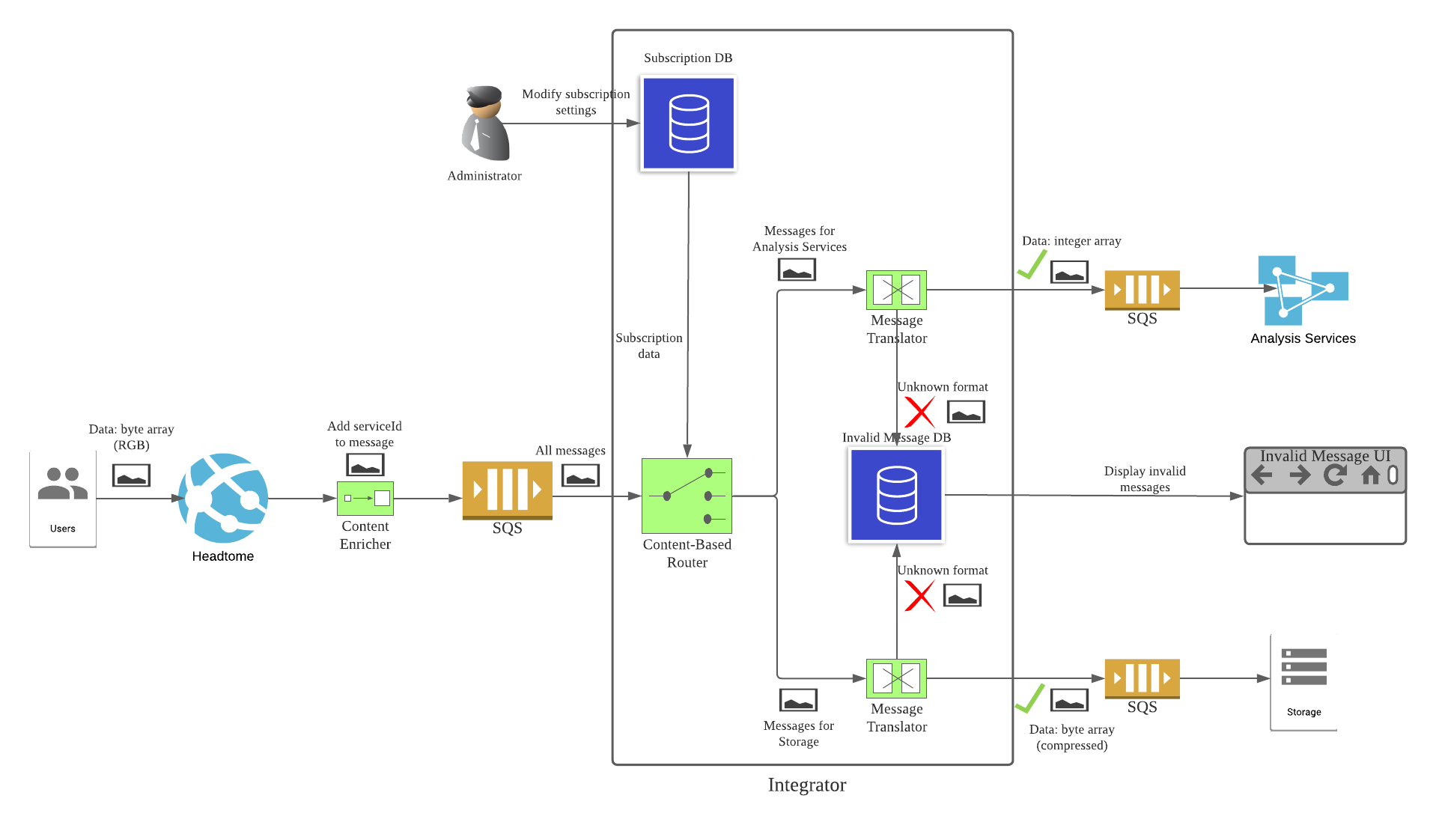
Alternatively, we can use the Invalid Message Channel pattern and send all invalid messages to a separate queue. Then we can have another service to pull messages from that queue and perform further processing.
The advantage of our messaging-based design
- Due to its asynchronous nature, we don’t lose data if a service goes down. Messages destined to that service will simply remain in the queue, waiting for it to recover.
- Each service can decide how fast (or slow) it wants to process messages in the queue. We can have mechanisms in place to determine if a service is being overloaded, and automatically reduce the consumption rate.
- Scaling out each service is dead easy. We don’t even need a load-balancer, just spin up new instances of the same service and let them pull from the same queue.
- By modifying records in the subscription database, an administrator can reconfigure the integrator on the fly without stopping other services.
- If we need to change the data format a service is using, this can be done by modifying only the corresponding translator. The senders and other receivers won’t know about this change.
Adding Rapidpound into the mix
With our design in place, adding Rapidpound is very simple.
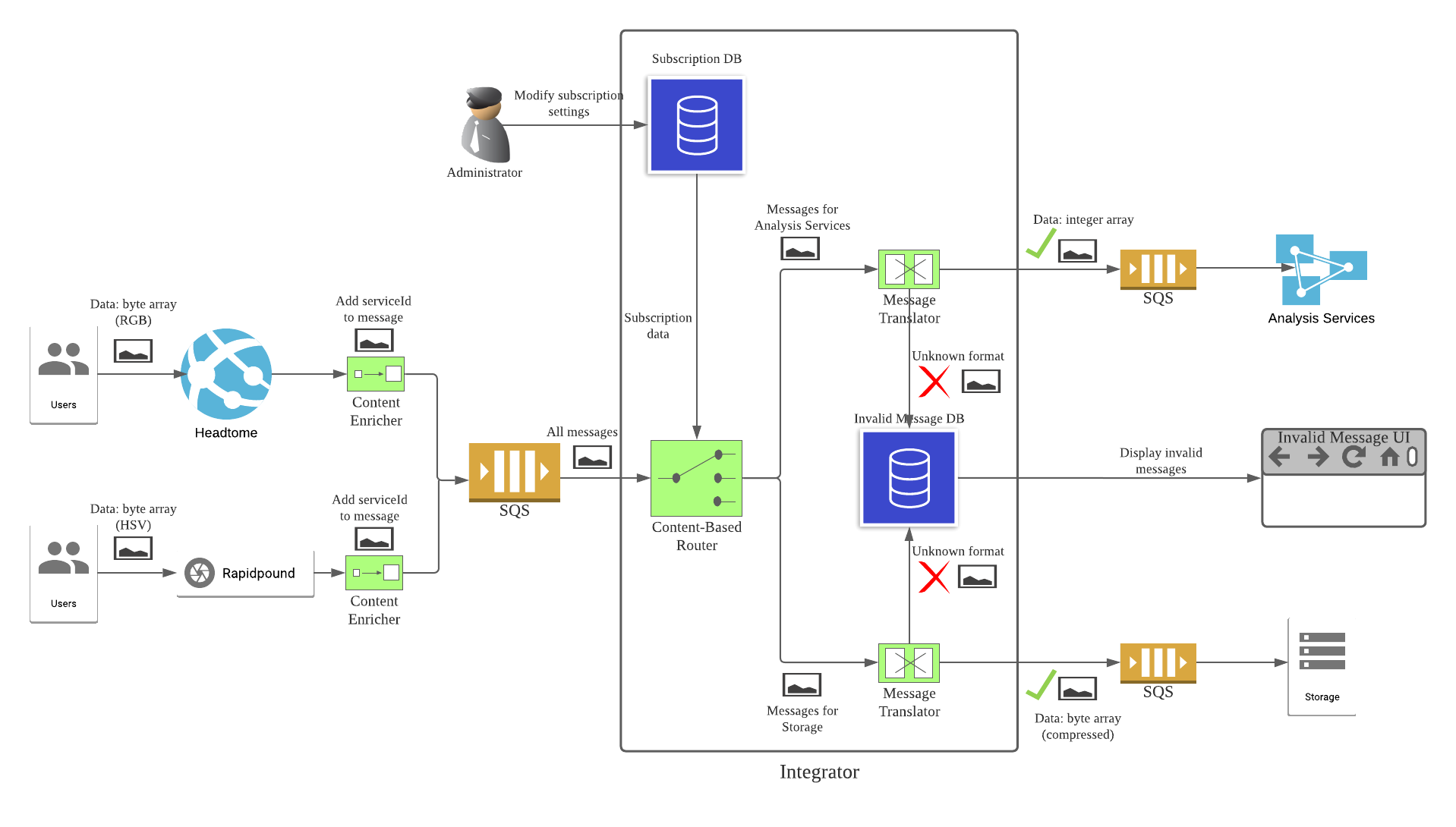
- Use a Content Enricher to add
serviceIdto messages from Rapidpound. - Create new records in the subscription database to subscribe the analysis service and the storage service to Rapidpound.
- Update each Message Translator to handle Rapidpound messages.
Other scenarios
Add a new receiver similar to the analysis service or the storage service.
- Create a SQS queue for the new service.
- Add a new Message Translator if necessary.
- Update the subscription database to subscribe the new service to senders. We can choose to receive messages from all senders, or from a selected group of senders.
Remove a receiver.
- Update the subscription database to remove all records pointing to that service.
- Remove the obsoleted Message Translator and SQS queue.
Remove a sender.
- Update the subscription database to remove all records subscribed to that service.
- Update all translators to remove the code to handle messages from that service.
As we can see, in all cases, modifying one service does not affect other parts in our system.
Conclusion
All design patterns in this article can be found in the book Enterprise Integration Patterns by Gregor Hohpe. Its second edition has just come out this summer, and I can’t wait to read it.
2 Thoughts on “Amazon SQS based services integration – Part two”