Note: phiên bản Tiếng Việt của bài này ở link dưới.
https://duongnt.com/kerastuner-vie
![]()
A deep learning model can use training data to learn the parameters in each layer on its own. But its architecture, the number and order of layers, and the number of filters in each layer,… must be tuned by humans. Although best practices exist, optimizing all these so-called hyperparameters is still as much art as it is science. Fortunately, we can automate part of the tuning process with packages like KerasTuner.
You can download all sample code from the link below.
https://gist.github.com/duongntbk/e35e1bd6bab5b0c1079236f227f17913
Prepare a training dataset
In this article, we will use the face dataset from this link. It has 1600 training samples, 340 validation samples, and 340 test samples; with 50% male and 50% female. I chose this dataset because it is relatively small, allowing me to train it in a reasonable amount of time with my not-so-good GPU. Alternatively, you can use your own dataset.
We can use the method below to load and preprocess all the data. We will convert all images to 150×150 pixels and rescale them into the [0, 1] range.
def load_data():
train_dataset = image_dataset_from_directory(
directory='dataset/train',
image_size=(150,150)
).map(lambda data, label: (data / 255., label))
val_dataset = image_dataset_from_directory(
directory='dataset/valid',
image_size=(150,150)
).map(lambda data, label: (data / 255., label))
test_dataset = image_dataset_from_directory(
directory='dataset/test',
image_size=(150,150)
).map(lambda data, label: (data / 255., label))
return train_dataset, val_dataset, test_dataset
Train a baseline model
Let’s train a baseline model. For most image processing problems, it is safe to start with a convolution network. Below is the architecture of our model.
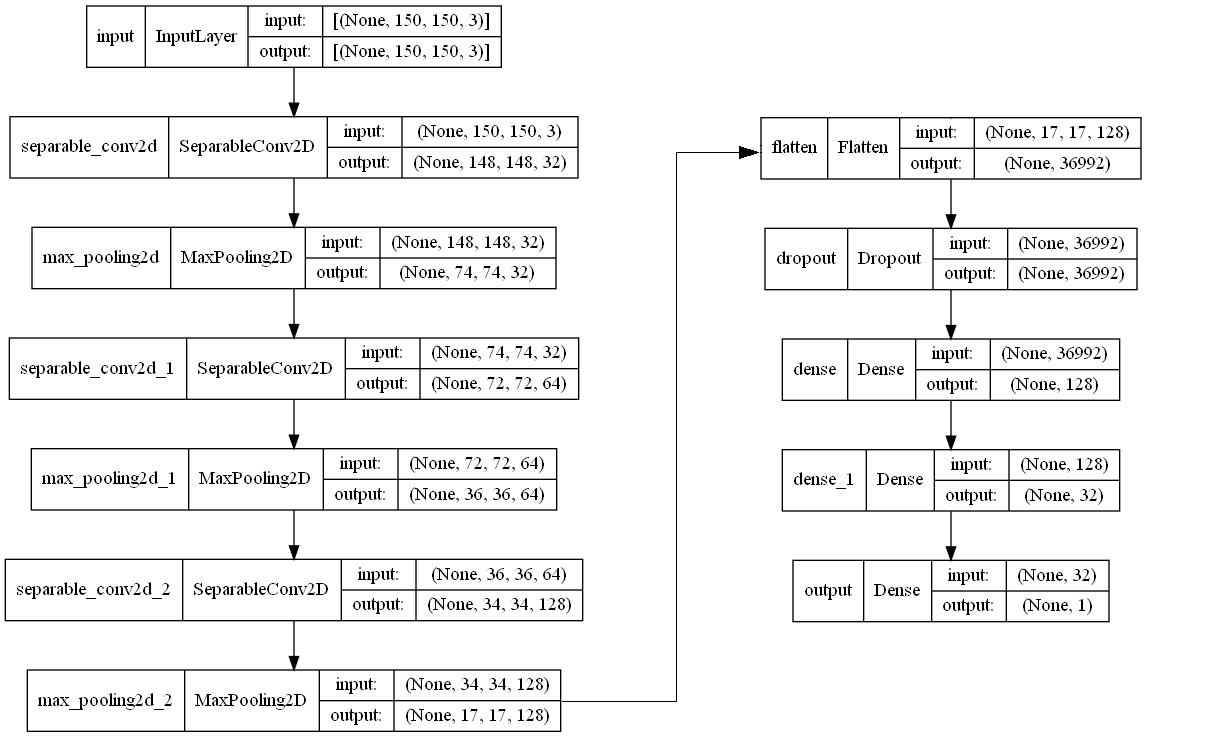
It consists of three SeparableConvolution2D layers and three Dense layers. I arbitrarily picked the number of filters in each layer and the dropout rate. But this should be a good enough start.
Note that we are using depthwise separable convolution layers instead of convolution layers here. This is because a depthwise separable layer requires much less calculation while still providing comparable results.
We train the model for 50 epochs, saving only the model with the best validation accuracy.
train_dataset, val_dataset, test_data = load_data()
model.fit(
train_dataset, epochs=50,
validation_data=val_dataset,
callbacks=[
keras.callbacks.ModelCheckpoint(
filepath='gender_prediction_baseline.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
Below is the validation loss and validation accuracy of the best epoch.
val_loss: 0.3562 - val_accuracy: 0.9118
And this is the test loss and test accuracy.
model.evaluate(test_dataset)
# [0.4990259110927582, 0.89705882352]
You can download the baseline model from this link.
Tuning the number of filters in each layer
Our baseline model can reach 89.7% accuracy on the test dataset. But from the loss/accuracy graph below, we can see that it overfitted right from the start.
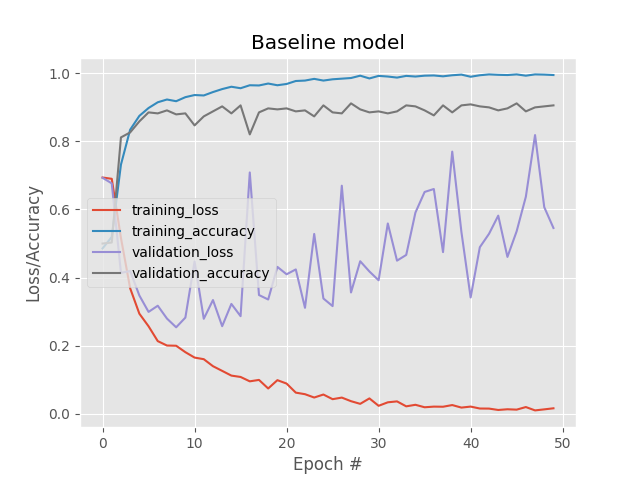
We can reduce the capacity of our model to fight overfitting. This means reducing the number of filters in each layer, increasing the dropout rate, removing layers…
Build a hyper model
We will use KerasTuner to tune the settings in each layer. The first step is to define a class that inherits from kt.HyperModel
class GenderClassificationHyperModel(kt.HyperModel):
#...
Then inside GenderClassificationHyperModel, we define a build method to create our model.
def build(self, hp):
inputs = keras.Input(shape=(150,150,3), name="input")
first_depth = hp.Int(name='first_depth', min_value=16, max_value=32, step=16)
features = layers.SeparableConvolution2D(first_depth, 3, activation='relu')(inputs)
features = layers.MaxPooling2D((2, 2))(features)
second_depth = hp.Int(name='second_depth', min_value=32, max_value=64, step=32)
features = layers.SeparableConvolution2D(second_depth, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
third_depth = hp.Int(name='third_depth', min_value=64, max_value=128, step=64)
features = layers.SeparableConvolution2D(third_depth, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
flatten = layers.Flatten()(features)
dropout_rate = hp.Float(name='dropout_rate', min_value=.3, max_value=.7, step=.1)
dense = layers.Dropout(dropout_rate)(flatten)
first_dense = hp.Int(name='first_dense', min_value=64, max_value=128, step=64)
dense = layers.Dense(first_dense, activation='relu')(dense)
second_dense = hp.Int(name='second_dense', min_value=16, max_value=32, step=16)
dense = layers.Dense(second_dense, activation='relu')(dense)
outputs = layers.Dense(1, activation='sigmoid', name='output')(dense)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
It’s easy to see that the code to build the model inside GenderClassificationHyperModel class is similar to the baseline code. The only difference is that we use KerasTuner to define the hyperparameters we want to tune. For example, the number of filters in the first separable convolution layers can vary from 16 to 32, in steps of 16.
first_depth = hp.Int(name='first_depth', min_value=16, max_value=32, step=16)
Similarly, the dropout rate can vary from 0.3 to 0.7, in steps of 0.1. Because the dropout rate is a floating point number, we use hp.Float instead of hp.Int.
dropout_rate = hp.Float(name='dropout_rate', min_value=.3, max_value=.7, step=.1)
Create a tuner
To start the tuning process, we need to create an object of type GenderClassificationHyperModel.
hp = GenderClassificationHyperModel()
Then we pass that object to a tuner object. There are multiple types of tuner, but we will use a BayesianOptimization.
tuner = kt.BayesianOptimization(hp, objective='val_accuracy',
max_trials=160, executions_per_trial=1, directory='gender_classifation', overwrite=True
)
Below are the meanings of each argument.
- objective: the value we try to optimize. In this case, we want to choose the model with the highest validation accuracy.
- max_trials: the maximum number of times we try to tune our number.
- executions_per_trial: the times to test each hyperparameter combination. We can train using the same combination multiple times to even out the differences caused by initial parameters randomization.
- directory: the path to store tuning history.
- overwrite: whether to overwrite old tuning history (if any).
Start the tuning process
We will try different combinations of hyperparameters, training each one for 50 epochs to find the one that gives the best validation accuracy. Then we perform further training using that combination. After 160 runs, we take the model with the highest validation accuracy.
tuner.search(train_dataset, batch_size=32, epochs=50,
validation_data=val_dataset, verbose=2,
callbacks=[
keras.callbacks.ModelCheckpoint(
filepath='gender_prediction_best.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
The best combination after 160 runs is below.
Hyperparameter |Best Value So Far
first_depth |32
second_depth |64
third_depth |64
dropout_rate |07
first_dense |128
second_dense |32
Which gives us the following architecture.
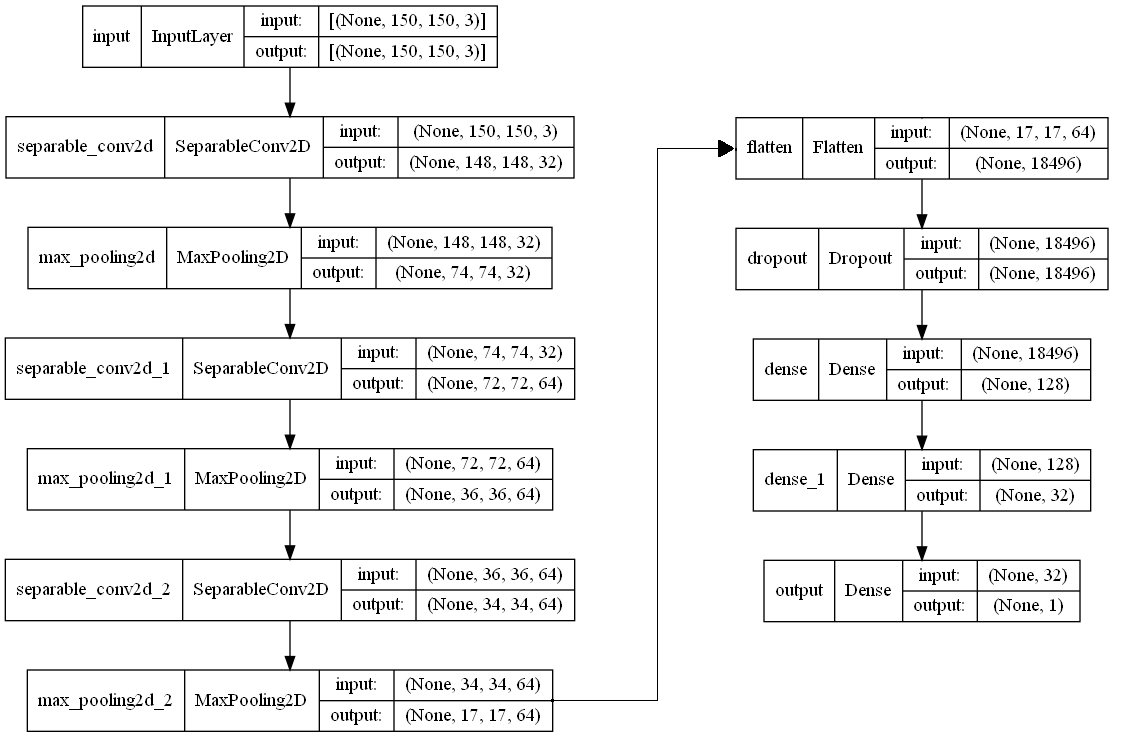
This is the validation loss and the validation accuracy of the best epoch.
val_loss: 0.2531 - val_accuracy: 0.9294
And this is the test loss and test accuracy.
model.evaluate(test_dataset)
# [0.42597368359565735, 0.908823549747467]
We’ve managed to increase validation accuracy by 2% and test accuracy by 1% compared to the baseline. You can download the new model from this link.
Tuning the number of layers
Build a hyper model with hp.Boolean
Let’s further reduce the capacity of our model by removing layers. Maybe we only need two separable convolution layers and two dense layers. This can also be automated with KerasTuner. Here is the modified build method. The interesting parts are below.
if hp.Boolean('three_conv_layer'):
# Add two more layers with 64 filters each
features = layers.SeparableConvolution2D(64, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
features = layers.SeparableConvolution2D(64, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
else:
# Add just one more layer with 128 filters
features = layers.SeparableConvolution2D(128, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
And
# The middle dense layer with 32 parameters can be removed
if hp.Boolean('second_dense_layer'):
dense = layers.Dense(32, activation='relu')(dense)
The new tuner
The step to create the tuner object stays largely the same. But this time, we only tune the hyperparameters 48 times. And we run each combination at least twice.
hp = GenderClassificationHyperModelV2()
tuner = kt.BayesianOptimization(hp, objective='val_accuracy',
max_trials=48, executions_per_trial=2, directory='gender_classifation_v2', overwrite=True
)
Prematurely stop the training
This time, we add a new callback to prematurely stop training if validation accuracy doesn’t improve after 10 epochs.
callbacks=[
keras.callbacks.ModelCheckpoint(
filepath='gender_prediction_best_v2.keras',
save_best_only='True',
monitor='val_accuracy'
),
keras.callbacks.EarlyStopping(
monitor='val_accuracy', patience=10
)
]
tuner.search(train_dataset, batch_size=32, epochs=50,
validation_data=val_dataset, verbose=2,
callbacks=callbacks)
After 48 runs, we find the best combination below.
Hyperparameter |Best Value So Far
three_conv_layer |True
dropout_rate |0.7
two_dense_layer |True
val_loss: 0.3284 - val_accuracy: 0.9235
The best model is still the one we found in the previous section. Moreover, the validation loss and the validation accuracy degraded somewhat. This is not too surprising, because the initial random value of parameters in each layer can cause minor variation in the final result.
Conclusion
Given that it can take hours or days to train a model, an exhausted search of all hyperparameter combinations is impossible. But KerasTuner can still help us automate part of the hyperparameters tuning process.
One Thought on “Auto hyperparameters tuning with KerasTuner”