Note: see the link below for the English version of this article.
https://duongnt.com/kerastuner
![]()
Các model deep learning có thể học giá trị các parameter trong từng layer dựa trên training data. Nhưng con người vẫn phải tự mình tối ưu hóa số layer, số filter trong từng layer,… Mặc dù có những quy chuẩn nhất định, việc điều chỉnh các hyperparameter đó vẫn phải dựa nhiều vào trực cảm. May mắn là chúng ta có thể tự động hóa một phần quá trình này nhờ vào những package như KerasTuner.
Các bạn có thể tải toàn bộ code ví dụ trong bài từ link dưới đây.
https://gist.github.com/duongntbk/e35e1bd6bab5b0c1079236f227f17913
Chuẩn bị training dataset
Trong bài này, chúng ta sẽ sử dụng dataset khuôn mặt từ đường link này. Dataset đó có 1600 dữ liệu training, 340 dữ liệu validation, và 340 dữ liệu test; trong đó có 50% là nam và 50% là nữ. Hoặc các bạn cũng có thể dùng bất kỳ dataset nào sẵn có.
Chúng ta dùng hàm dưới đây để đọc và preprocess dữ liệu. Ta chuyển tất cả ảnh về kích cỡ 150×150 pixel, và chuẩn hóa giá trị từng ảnh vào trong khoảng [0, 1].
def load_data():
train_dataset = image_dataset_from_directory(
directory='dataset/train',
image_size=(150,150)
).map(lambda data, label: (data / 255., label))
val_dataset = image_dataset_from_directory(
directory='dataset/valid',
image_size=(150,150)
).map(lambda data, label: (data / 255., label))
test_dataset = image_dataset_from_directory(
directory='dataset/test',
image_size=(150,150)
).map(lambda data, label: (data / 255., label))
return train_dataset, val_dataset, test_dataset
Train một model làm cơ sở so sánh
Ta sẽ train một model làm cơ sở so sánh. Khi gặp một bài toán về xử lý ảnh, đầu tiên ta nên thử sử dụng convolution network. Dưới đây là kiến trúc của model.
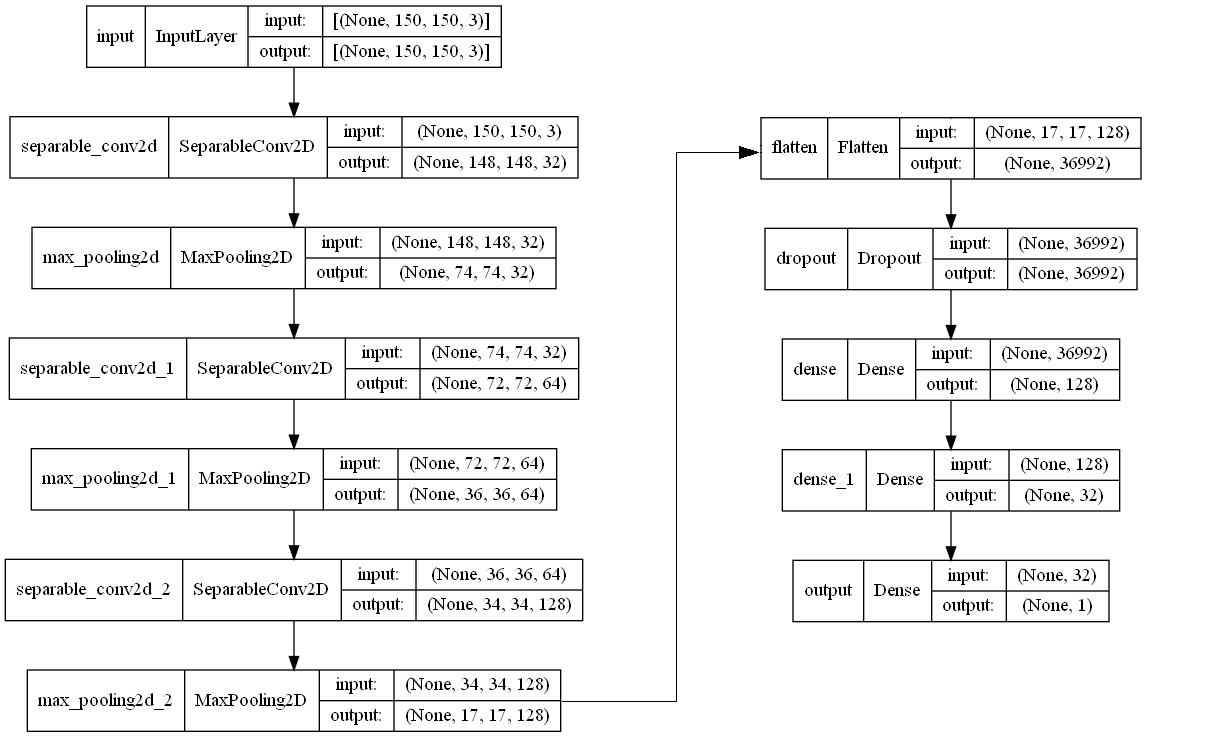
Model này có 3 layer SeparableConvolution2D và 3 layer Dense. Tôi chọn áng chừng tỷ lệ dropout và số filter trong từng layer, nhưng model này là đủ để làm cơ sở.
Chú ý là ở đây ta sử dụng depthwise separable convolution layer thay vì convolution layer. Nguyên nhân vì depthwise separable layer thực hiện ít tính toán hơn, nhưng lại cho kết quả gần tương đương với convolution layer.
Ta sẽ train model này trong 50 epoch và chỉ lưu lại model nào có validation accuracy cao nhất.
train_dataset, val_dataset, test_data = load_data()
model.fit(
train_dataset, epochs=50,
validation_data=val_dataset,
callbacks=[
keras.callbacks.ModelCheckpoint(
filepath='gender_prediction_baseline.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
Dưới đây là validation loss và validation accuracy của epoch tốt nhất.
val_loss: 0.3562 - val_accuracy: 0.9118
Và đây là test loss cùng test accuracy.
model.evaluate(test_dataset)
# [0.4990259110927582, 0.89705882352]
Các bạn có thể tải về model này tại đây.
Điều chỉnh số filter trong từng layer
Model cơ sở của ta đạt độ chính xác 89.7% trên test dataset. Nhưng từ biểu đồ loss/accuracy dưới đây, ta có thể thấy rằng nó bị overfit từ rất sớm.
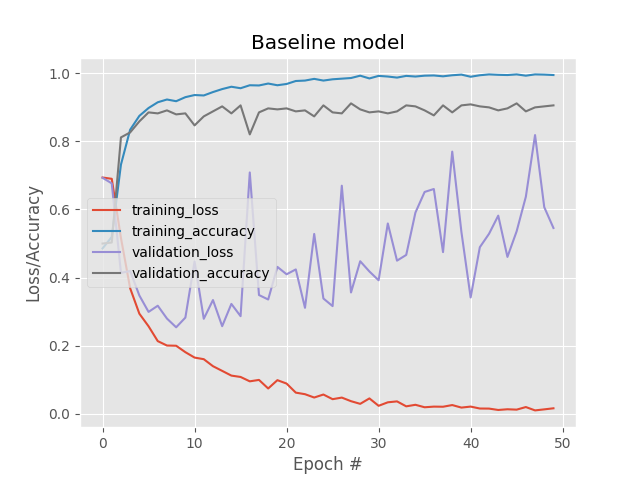
Ta có thể cải thiện tình trạng này bằng cách giảm capacity của model. Có nghĩa là ta cần giảm số filter trong các layer, tăng tỷ lệ dropout, giảm số layer,…
Tạo hyper model
Ta sẽ dùng KerasTuner để điều chỉnh thiết lập của từng layer. Bước đầu tiên là tạo một lớp kế thừa từ kt.HyperModel.
class GenderClassificationHyperModel(kt.HyperModel):
#...
Sau đó ta cần định nghĩa hàm build để tạo model bên trong lớp GenderClassificationHyperModel.
def build(self, hp):
inputs = keras.Input(shape=(150,150,3), name="input")
first_depth = hp.Int(name='first_depth', min_value=16, max_value=32, step=16)
features = layers.SeparableConvolution2D(first_depth, 3, activation='relu')(inputs)
features = layers.MaxPooling2D((2, 2))(features)
second_depth = hp.Int(name='second_depth', min_value=32, max_value=64, step=32)
features = layers.SeparableConvolution2D(second_depth, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
third_depth = hp.Int(name='third_depth', min_value=64, max_value=128, step=64)
features = layers.SeparableConvolution2D(third_depth, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
flatten = layers.Flatten()(features)
dropout_rate = hp.Float(name='dropout_rate', min_value=.3, max_value=.7, step=.1)
dense = layers.Dropout(dropout_rate)(flatten)
first_dense = hp.Int(name='first_dense', min_value=64, max_value=128, step=64)
dense = layers.Dense(first_dense, activation='relu')(dense)
second_dense = hp.Int(name='second_dense', min_value=16, max_value=32, step=16)
dense = layers.Dense(second_dense, activation='relu')(dense)
outputs = layers.Dense(1, activation='sigmoid', name='output')(dense)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
Dễ dàng thấy rằng code tạo model trong lớp GenderClassificationHyperModel rất giống code của model cơ sở. Điểm khác biệt duy nhất là ta dùng KerasTuner để khai báo các hyperparameter mình muốn điều chỉnh. Ví dụ: số filter trong separable convolution layer đầu tiên có thể nhận giá trị 16 hoặc 32.
first_depth = hp.Int(name='first_depth', min_value=16, max_value=32, step=16)
Tương tự trên, tỷ lệ dropout có thể nhận giá trị là 0.3, 0.4, 0.5, 0.6 hoặc 0.7. Vì tỷ lệ này có kiểu là float nên ta sử dụng hp.Float thay vì hp.Int.
dropout_rate = hp.Float(name='dropout_rate', min_value=.3, max_value=.7, step=.1)
Tạo đối tượng tuner
Để bắt đầu quả trình tối ưu hóa, ta cần tạo một object thuộc lớp GenderClassificationHyperModel.
hp = GenderClassificationHyperModel()
Sau đó ta truyền object này vào một tuner. Có nhiều kiểu tuner, nhưng ta sẽ sử dụng BayesianOptimization.
tuner = kt.BayesianOptimization(hp, objective='val_accuracy',
max_trials=160, executions_per_trial=1, directory='gender_classifation', overwrite=True
)
Dưới đây là ý nghĩa của từng tham số.
- objective: giá trị ta dùng để tối ưu. Trong bài này ta sẽ chọn ra model có validation accuracy cao nhất.
- max_trials: thực hiện tối đa 160 lần chạy test.
- executions_per_trial: số lần test từng tổ hợp hyperparameter. Ta có thể train model sử dụng cùng một tổ hợp hyperparameter nhiều lần để giảm bớt sai số tạo bởi quá trình khởi tạo ngẫu nhiên các layer.
- directory: đường dẫn để lưu lịch sử tối ưu.
- overwrite: có ghi đè lịch sử tối ưu hay không.
Bắt đầu quá trình tối ưu
Ta sẽ thử train từng tổ hợp hyperparameter trong 50 epoch để tìm ra tổ hợp cho ta validation accuracy cao nhất. Sau đó ta sẽ tiếp tục train bằng tổ hợp đó. Sau 160 lượt test, ta sẽ lấy ra model với validation accuracy cao nhất.
tuner.search(train_dataset, batch_size=32, epochs=50,
validation_data=val_dataset, verbose=2,
callbacks=[
keras.callbacks.ModelCheckpoint(
filepath='gender_prediction_best.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
Dưới đây là tổ hợp tốt nhất sau 160 lần test.
Hyperparameter |Best Value So Far
first_depth |32
second_depth |64
third_depth |64
dropout_rate |07
first_dense |128
second_dense |32
Nó tương ứng với kiến trúc dưới đây.
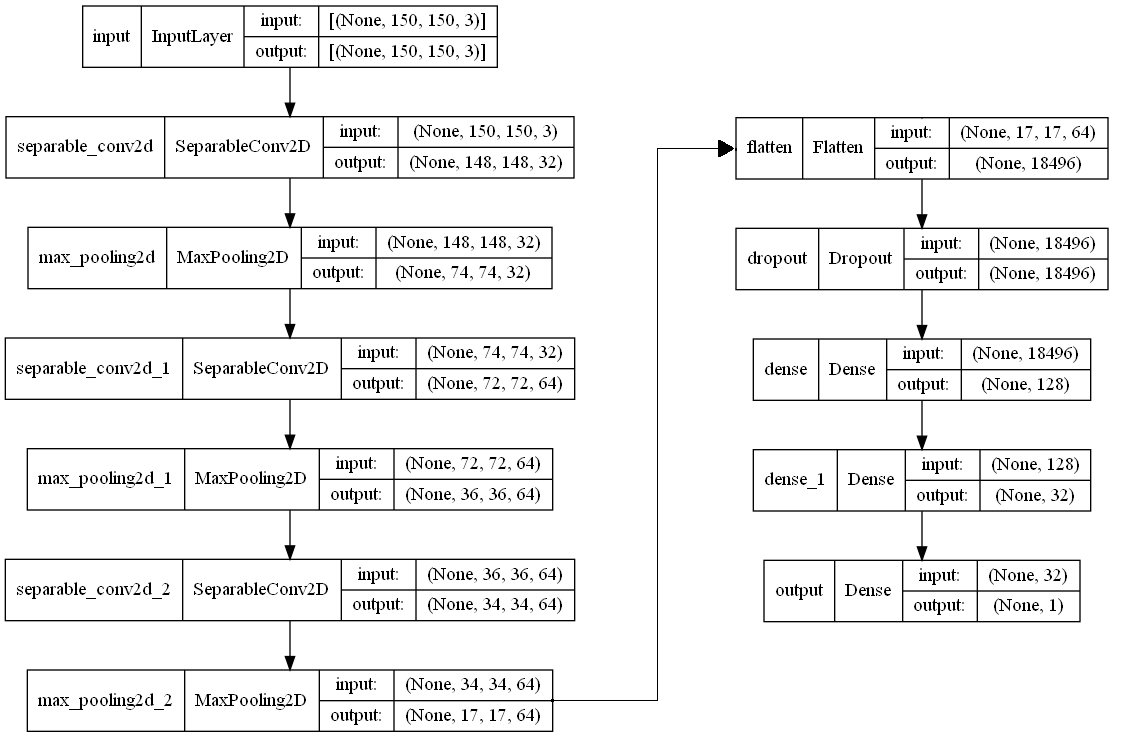
Đây là validation loss và validation accuracy của epoch tốt nhất.
val_loss: 0.2531 - val_accuracy: 0.9294
Và đây là test loss cùng test accuracy.
model.evaluate(test_dataset)
# [0.42597368359565735, 0.908823549747467]
Chúng ta đã cải thiện validation accuracy được 2% và cải thiện test accuracy được 1%. Các bạn có thể download model mới tại đây.
Điều chỉnh số layer
Tạo hyper model bằng hp.Boolean
Ta sẽ thử giảm capacity của model hơn nữa bằng cách loại bỏ bớt layer. Có thể ta chỉ cần 2 separable convolution layer và 2 dense layer. Quá trình test này cũng có thể được tự động hóa bằng KerasTuner. Đây là hàm build mới. Nó có các điểm đáng chú ý sau đây.
if hp.Boolean('three_conv_layer'):
# Thêm 2 layer với 64 filter trong từng layer
features = layers.SeparableConvolution2D(64, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
features = layers.SeparableConvolution2D(64, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
else:
# Thêm 1 layer với 128 filter
features = layers.SeparableConvolution2D(128, 3, activation='relu')(features)
features = layers.MaxPooling2D((2, 2))(features)
Và
# Ta có thể bỏ bớt dense layer ở giữa
if hp.Boolean('second_dense_layer'):
dense = layers.Dense(32, activation='relu')(dense)
Tuner mới
Bước tạo object tuner không có nhiều thay đổi. Nhưng lần này ta chỉ chạy 48 lượt test. Và ta sẽ test mỗi tổ hợp ít nhất 2 lần.
hp = GenderClassificationHyperModelV2()
tuner = kt.BayesianOptimization(hp, objective='val_accuracy',
max_trials=48, executions_per_trial=2, directory='gender_classifation_v2', overwrite=True
)
Dừng quá trình training sớm
Lần này, ta sẽ thêm một callback mới để dừng quá trình training nếu như validation accuracy không được cải thiện sau 10 epoch.
callbacks=[
keras.callbacks.ModelCheckpoint(
filepath='gender_prediction_best_v2.keras',
save_best_only='True',
monitor='val_accuracy'
),
keras.callbacks.EarlyStopping(
monitor='val_accuracy', patience=10
)
]
tuner.search(train_dataset, batch_size=32, epochs=50,
validation_data=val_dataset, verbose=2,
callbacks=callbacks)
Sau 48 lượt test, ta tìm được tổ hợp tối ưu nhất như sau.
Hyperparameter |Best Value So Far
three_conv_layer |True
dropout_rate |0.7
two_dense_layer |True
val_loss: 0.3284 - val_accuracy: 0.9235
Model tốt nhất vẫn là model ta đã tìm được trong phần trước. Hơn nữa, giá trị validation loss và validation accuracy bị kém đi đôi chút. Điều này không phải quá kỳ lạ, vì quá trình khởi tạo ngẫu nhiên các layer có thể ảnh hưởng một chút tới kết quả cuối cùng.
Kết thúc
Quá trình train một model có thể tốn nhiều giờ, thậm chí nhiều ngày. Vì thế ta không thể chạy vét cạn tất cả các tổ hợp của hyperparameter. Nhưng KerasTuner vẫn có thể giúp ta tự động hóa phần nào quá trình tìm kiếm này.
One Thought on “Tối ưu hóa hyperparameter với KerasTuner”