Note: phiên bản Tiếng Việt của bài này ở link dưới.
https://duongnt.com/restore-vietnamese-diacritics-vie
Even though the Vietnamese alphabet is based on the Latin script, it has some extra diacritics. For example, aside from a, we also have ă,â,à,ả,ã,á,ạ,.... They help to produce an accurate representation of the Vietnamese language. Unlike in other languages such as English, if you can spell a word in Vietnamese, then you will know how to pronounce it.
Unfortunately, sometimes due to technical limitations, we have to type Vietnamese without diacritics. While it is possible to read Vietnamese without those diacritics and still more or less understand the meaning, it can lead to some amusing misunderstandings. A running joke in Vietnamese is that vợ đẻ (wife gives birth) and vỡ đê (the dike breaks) are both vo de without diacritics.
Today, we will use a Transformer model to restore diacritics for Vietnamese texts. Our approach will take inspiration from how machine translation works.
You can download all the sample code from the link below.
https://github.com/duongntbk/restore_vietnamese_diacritics
And you can download the model and the saved vectorization files from this link.
https://drive.google.com/drive/folders/1duBcp3YTsKeYz8xQThBsDjEUx3zRoLS3
Use a Transformer model to restore Vietnamese diacritics
The Transformer model
Traditionally, RNN models like LSTM or GRU dominated the NLP landscape. But after its introduction in 2017, the Transformer model has become the go-to choice for many NLP problems, one of which is machine translation. In fact, this is the same technology behind Google Translate.
Below is the architecture of an end-to-end Transformer model. This picture is taken from page 359 of the book Deep Learning with Python by Francois Chollet.
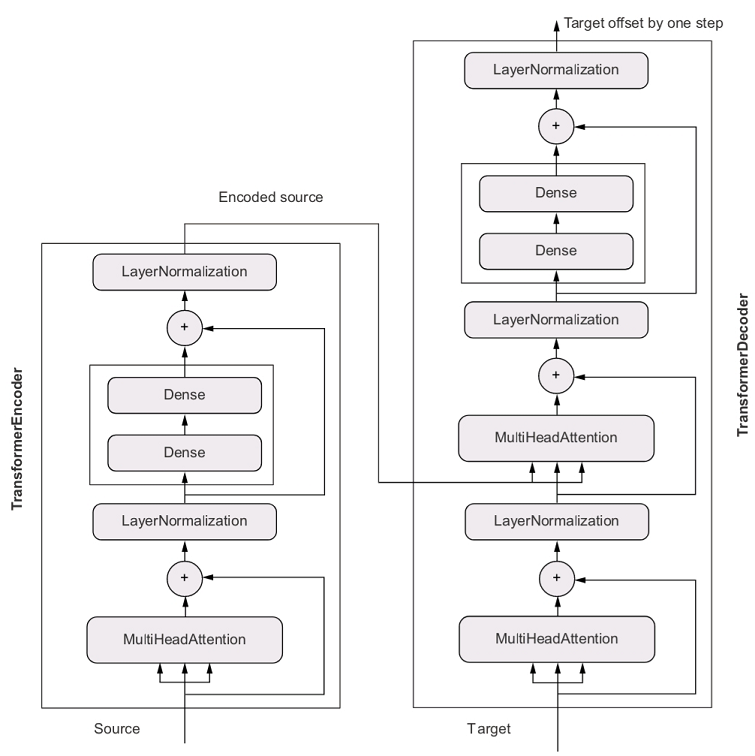
As we can see from the diagram, a Transformer model consists of an encoder and a decoder. They work together to map texts from a source to a target.
Transformer model and machine translation
The role of the encoder is to turn the source text into a set of vectors that form an encoded representation of the input. But at the same time, the encoder keeps this representation in a sequence format. This means our vectors are context-aware.
The role of the decoder is to generate the output. Given N tokens from the output, it will use those tokens and the encoded representation of the input to predict the N+1 token in the output. While doing this, it can identify which token in the input is most closely related to the next token it is predicting. This helps the decoder best utilize the whole context of the input. Perhaps you might wonder how we can get the first token from the output to kick-start the entire process. The answer is that we use a dummy token as a seed in the first step.
Assuming that we have padded all target texts with the seed word [Start] and the stop word [End] in training, below is how we use the Transformer model to translate I have a dream to Tôi có một giấc mơ.
- Run
I have a dreamthrough the encoder to retrieve an encoded representation. - Run the encoded representation and the seed word
[Start]through the decoder to (hopefully) get the first wordTôi. - Append
Tôito the seed word to get[Start] Tôi. - Run the encoded representation and the current output
[Start] Tôithrough the decoder again to get the wordcó. - Repeat the two steps above until we meet the stop word
[End]. If everything went as plan, the output should be[Start] Tôi có một giấc mơ [End]. - Strip the seed word and the stop word to retrieve the final result:
Tôi có một giấc mơ.
What does machine translation have to do with our problem?
After reading about machine translation with Transformer, I had this crazy idea. Maybe we can consider Vietnamese without diacritics as a whole new language and try to translate it back to proper Vietnamese. Compared to a normal machine translation problem, we have some big advantages.
- Given a Vietnamese text, it’s dead easy to convert it to the diacritics-less version. Because of that, we can skip the proofreading step when creating a training dataset.
- A normal Vietnamese text and its diacritics-less version always have the same number of words. We don’t need a stop word to train our model; just a seed word is enough.
- A diacritics-less word can only be mapped to a limited number of Vietnamese words. For example,
macan only be mapped toma/mà/mả/mã/má/mạ. Hopefully, our model can learn this limitation from the data.
Based on that, I believe that translating from diacritics-less Vietnamese to proper Vietnamese can achieve much higher accuracy than normal machine translation.
Prepare a training dataset
We will use the Old Newspapers dataset from Kaggle in today’s article. It has around 16 million sentences, but only 720,000 or so are in Vietnamese. This dataset is stored as a tsv file and is nearly 6 GB. I wrote this simple console application called VietnameseCrawler to read the whole corpus, extract every Vietnamese sentence, and export them along with their diacritics-less version to a new file.
We can run our application from the command line.
dotnet run <path to input file> <path to output file>
Below are some examples from the output file.
cac nhac sy do deu dang duoc vinh danh ca -> các nhạc sỹ đó đều đáng được vinh danh cả
cai ma ngay nay cho nao cung thieu -> cái mà ngày nay chỗ nào cũng thiếu
gia ve dao dong tu 78 den 158 usd -> giá vé dao động từ 78 đến 158 usd
khong cho phep tre em duoi 4 tuoi -> không cho phép trẻ em dưới 4 tuổi
The first training attempt
Preprocessing
As usual, the code to train models is written in Python, using the Keras framework. First, we need to load data from the text file. Then we split it into training set, validation set, and test set.
from data_loader import load_data
file_path = 'dataset/old-newspaper-vietnamese.txt'
train_pairs, val_pairs, test_pairs = load_data(file_path, limit=10000)
Note that we only load the first 10,000 sentences from the text file. This is because we want to run some experiments before committing to training on the full corpus.
We create a source vectorization and a target vectorization from the training dataset. These vectorization objects can be used to convert plain text data into tensors, so that we can train a deep learning model on them. Remember to save those vectorization objects to disk.
from data_loader import load_data, save_vectorization
source_vectorization, target_vectorization = create_vectorizations(train_pairs)
save_vectorization(source_vectorization, 'result/source_vectorization_layer.pkl')
save_vectorization(target_vectorization, 'result/target_vectorization_layer.pkl')
The next step is to convert our plain text dataset into tf.data.Dataset objects. We will have a separate tf.data.Dataset for the training set, validation set, and test set.
from data_loader import make_dataset
batch_size = 64
train_ds = make_dataset(train_pairs, source_vectorization, target_vectorization, batch_size)
val_ds = make_dataset(val_pairs, source_vectorization, target_vectorization, batch_size)
test_ds = make_dataset(test_pairs, source_vectorization, target_vectorization, batch_size) # We will use this in the evaluation step
Train model with the TransformerModel class
We train our model using the TransformerModel class. At first, we will keep the default settings of 256 dimensions in embed layer, 2048 dimensions in Dense layer of Transformer, 8 attention heads, and dropout with 0.5 rate.
from transformer_model import TransformerModel
transformer = TransformerModel(source_vectorization=source_vectorization,
target_vectorization=target_vectorization)
Finally, we can build the model and start training. We will train for 50 epochs and only keep the model with the highest validation accuracy.
transformer.build_model(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
transformer.fit(train_ds, epochs=50, validation_data=val_ds,
callbacks=[
tf.keras.callbacks.ModelCheckpoint(
filepath='result/restore_diacritic.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
The first result
Since we trained on only 10,000 sentences, the model did not take long to coverage. On my low-end GPU, 50 epochs took around 30 minutes. However, the test accuracy and test loss are not very high. We reached 0.6837 test loss and 69.13% test accuracy. This means our model predicts the next token correctly 69.13% of the time.
transformer.evaluate(test_ds) # Print [0.6836796998977661, 0.691321611404419]
Let’s take a look at the loss/accuracy by epochs.
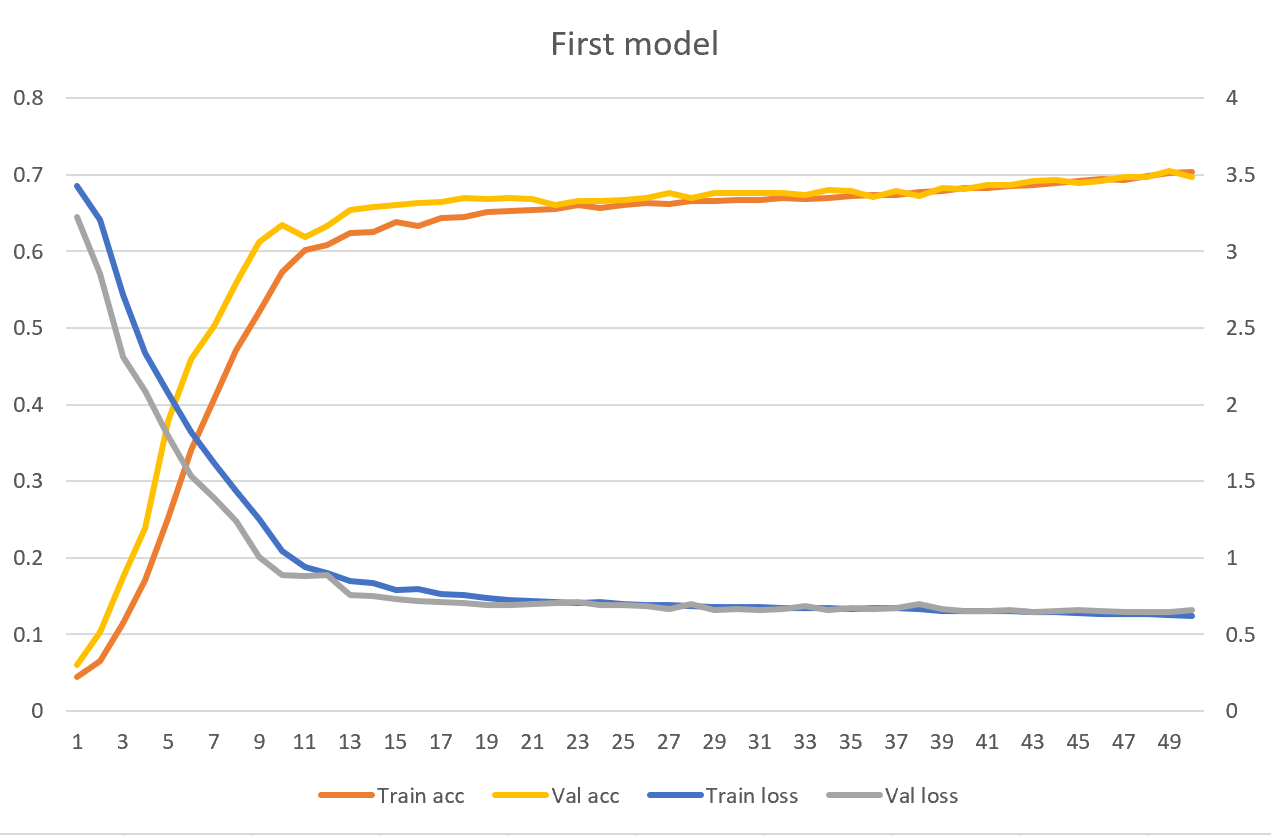
We can see that the validation loss/accuracy is comparable to training loss/accuracy. This means our model is underfitting. The default settings do not have enough capacity to handle our translation.
Increase the model’s capacity
There are a few ways to increase the capacity of our model. We can increase the number of dimensions in the embed layer and dense layer of the Transformer, increase the number of attention heads, and reduce the dropout rate. Unfortunately, even the default settings are already pushing my GPU to its limit. I cannot increase the dimensions of the embed layer past 256. And 16 attention heads is the maximum amount my GPU can handle without throwing an out of memory exception.
Next, we will train two models on 300,000 sentences with the following settings.
- Settings 1: 8,192 dimensions in Dense layer of Transformer, 8 attention heads, and dropout with a 0.2 rate.
- Settings 2: 2,048 dimensions in Dense layer of Transformer, 16 attention heads, and dropout with a 0.2 rate.
The results are below.
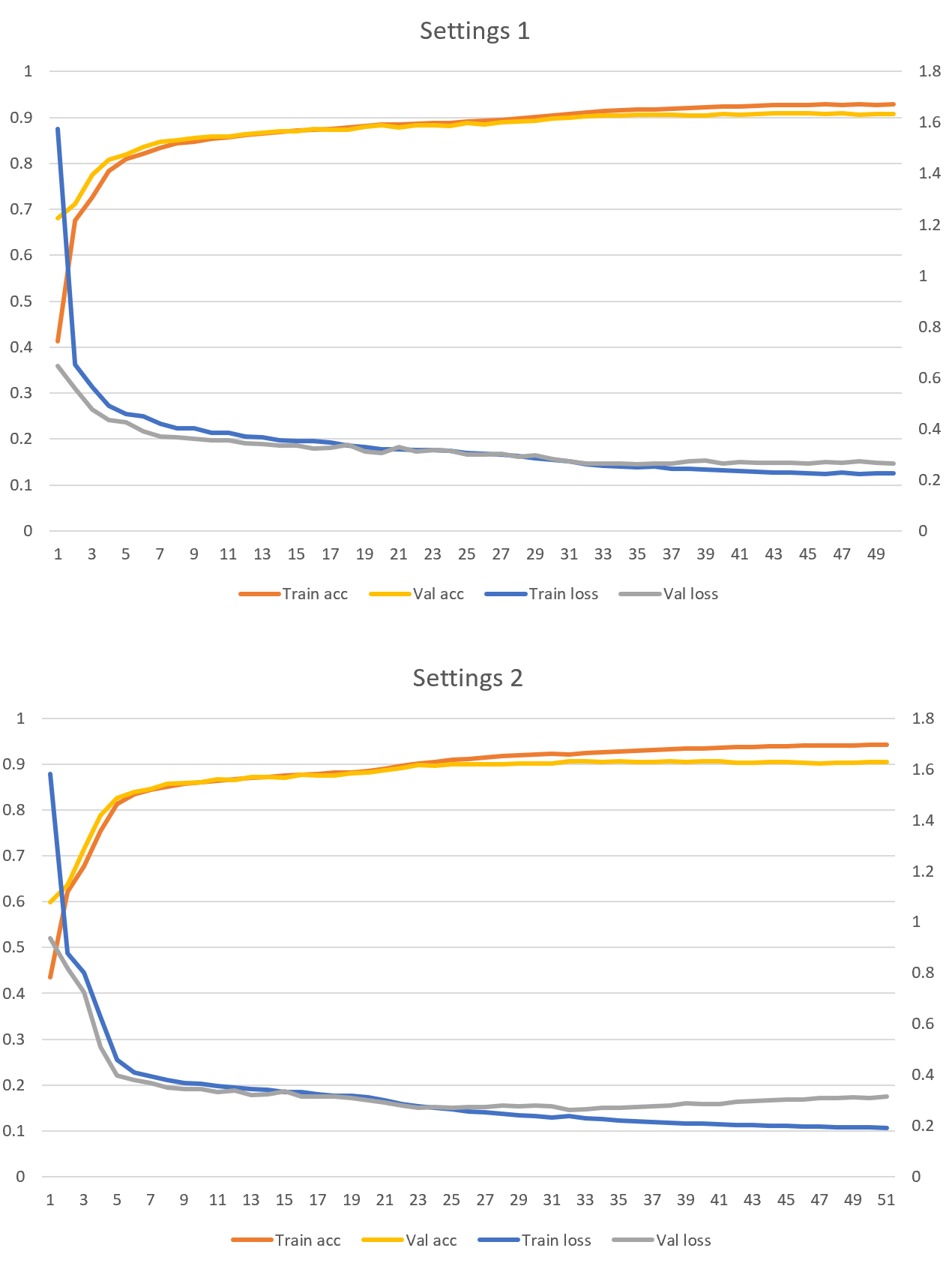
We achieved over 90% validation accuracy. This is to be expected because we trained on more data. Both settings above have similar accuracy, but Settings 1 runs 20% faster on my GPU. Moreover, we haven’t seen any overfitting in either case yet.
Training on the full corpus
Given the result in the last section, we will use Settings 1 to train a model on the full corpus. But this time, we remove the Dropout layer altogether.
train_pairs, val_pairs, test_pairs = load_data(file_path, limit=None)
# ...omitted
transformer = TransformerModel(source_vectorization=source_vectorization,
target_vectorization=target_vectorization,
dense_dim=8192, num_heads=8, drop_out=0)
This time, the model took more than 2 days to coverage. Below is the result.
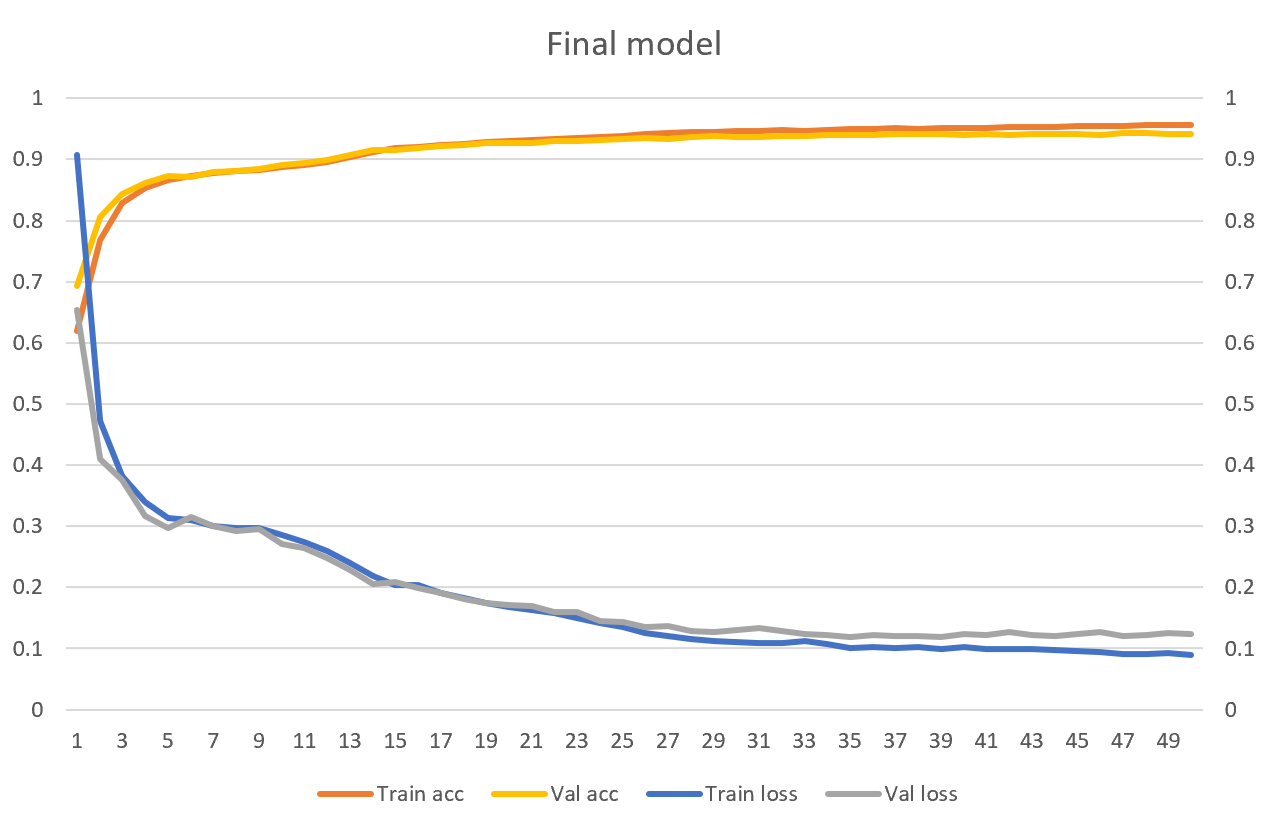
transformer.evaluate(test_ds) # [0.12277301400899887, 0.9405344128608704]
We have reached 94.05% test accuracy. I believe we can still improve our model by increasing its capacity. Unfortunately, this is already the limit of my GPU.
Some examples
Let’s try running some Vietnamese sentences through our model.
texts = [
'ten toi la thai duong',
'toi sinh ra o ha noi',
'ngay mai troi se nang'
]
for text in texts:
print(transformer.predict(text))
| Original | Diacritics-less | English | Model’s output |
|---|---|---|---|
| tên tôi là thái dương | ten toi la thai duong | my name is thai duong | tên tôi là thái dương |
| tôi sinh ra ở hà nội | toi sinh ra o ha noi | I was born in hanoi | tôi sinh ra ở hà nội |
| ngày mai trời sẽ nắng | ngay mai troi se nang | it’ll be sunny tomorrow | ngày mai trời sẽ nắng |
How to resume training
As mentioned earlier, our model took two days to coverage when training on the full corpus. Because of that, being able to pause and resume training is beneficial. Fortunately, this is easy with Keras.
from data_loader import load_vectorization_from_disk
source_vectorization = load_vectorization_from_disk('<path to source vectorization file>')
target_vectorization = load_vectorization_from_disk('<path to target vectorization file>')
# ...omitted
transformer = TransformerModel(source_vectorization=source_vectorization,
target_vectorization=target_vectorization,
model_path='<path to saved model>')
transformer.fit(train_ds, epochs=50, validation_data=val_ds,
callbacks=[
tf.keras.callbacks.ModelCheckpoint(
filepath='result/restore_diacritic.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
Conclusion
Restoring Vietnamese diacritics with Transformer is an interesting problem with real-world application. I found this article from my alma mater (my classmates might remember Dr. Trang, who taught us Object-oriented programming in our 3rd year). They used Transformer in a hybrid approach to restore diacritics at the character level (instead of the word level). And they claimed 98.37% test accuracy. But they had access to a Tesla V100 PCIe GPU and also used a dataset 15 times bigger than mine.
I sure wish I had a Tesla V100 lying around :). Maybe I can achieve similar accuracy if I can increase the capacity of my model and train it on a bigger dataset. Either way, I feel that for a toy project, 94.05% test accuracy is not too bad.
One Thought on “Restore Vietnamese diacritics with Transformer”