Note: see the link below for the English version of this article.
https://duongnt.com/restore-vietnamese-diacritics
Chắc chúng ta ai cũng đã từng nghe câu chuyện cười rằng vỡ đê hay vợ đẻ khi viết không dấu đều là vo de. Mặc dù việc đọc Tiếng Việt không dấu không phải là quá khó khăn, có lẽ tất cả mọi người đều thích đọc Tiếng Việt có dấu hơn.
Hôm nay, chúng ta sẽ sử dụng Transformer để thêm dấu cho Tiếng Việt không dấu. Giải pháp này sẽ áp dụng các kỹ thuật thường được sử dụng trong machine translation.
Các bạn có thể download toàn bộ code ví dụ từ đường link dưới đây.
https://github.com/duongntbk/restore_vietnamese_diacritics
Và các bạn có thể download model cùng file vectorization từ đường link dưới đây.
https://drive.google.com/drive/folders/1duBcp3YTsKeYz8xQThBsDjEUx3zRoLS3
Dùng Transformer để thêm dấu cho Tiếng Việt
Transformer là gì?
Trước đây, các model RNN như LSTM hay GRU thường được sử dụng để giải quyết các bài toán NLP. Nhưng sau khi được giới thiệu vào năm 2017, Transformer đã nhanh chóng trở thành lựa chọn số một cho các vấn đề NLP, mà một trong số đó là bài toán machine translation. Đây cũng chính là công nghệ mà Google Translate đang sử dụng.
Dưới đây là kiến trúc của một model Transformer đầu cuối. Sơ đồ này được lấy từ trang 359 của cuốn sách Deep Learning with Python by Francois Chollet.
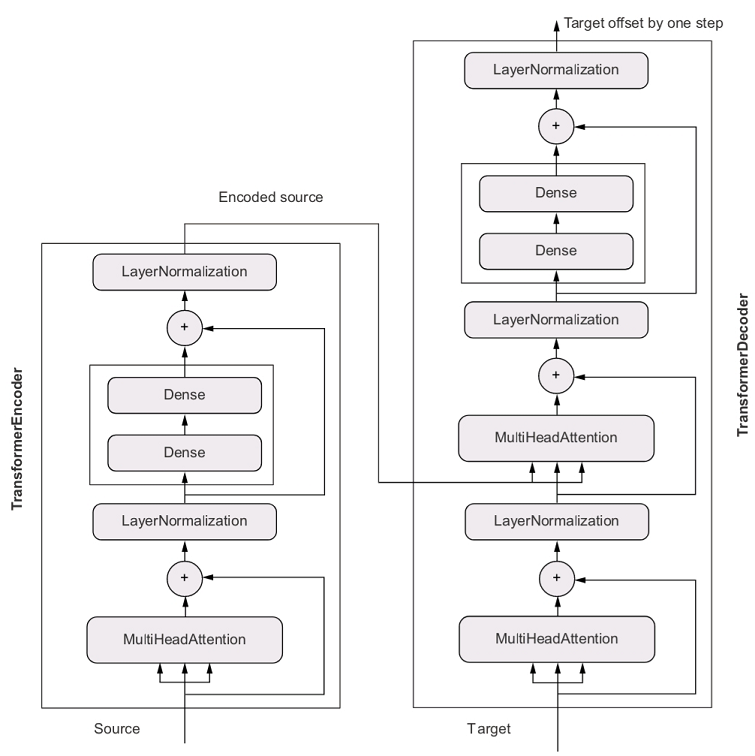
Như ta thấy từ sơ đồ, một model Transformer được cấu thành từ 2 phần là encoder và decoder. Chúng kết hợp với nhau để ánh xạ một đoạn văn trong tập nguồn tới đoạn văn tương ứng trong tập đích.
Transformer và machine translation
Nhiệm vụ của encoder là chuyển đoạn văn nguồn thành tập các vector. Những vector này tạo thành encoded representation của đầu vào. Đồng thời, encoder đảm bảo tính tuần từ cho encoded representation này. Có nghĩa là các vector của ta vẫn giữ được thông tin về ngữ nghĩa của toàn đoạn văn.
Nhiệm vụ của decoder là sinh dữ liệu đầu ra. Nó sử dụng N token của dữ liệu đầu ra và kết hợp với encoded representation của đầu vào để dự đoán token thứ N+1 của đầu ra. Trong quá trình này, nó có thể nhận biết được token nào trong đầu vào có mối liên hệ mật thiết nhất với token tiếp theo mà nó đang dự đoán. Điều này giúp decoder tận dụng tối đa được ngữ nghĩa của đầu vào. Có lẽ các bạn sẽ hỏi làm thế nào ta có được token thứ nhất của đầu ra để kích hoạt quá trình trên? Câu trả lời là ta sẽ sử dụng một token mồi trong bước đầu tiên.
Giả sử ta đã thêm token mồi [Start] và token kết thúc [End] vào tất cả các đoạn văn trong training data, các bước sử dụng Transformer để dịch I have a dream thành Tôi có một giấc mơ là như sau.
- Chạy câu
I have a dreamqua encoder để lấy encoded representation. - Kết hợp encoded representation và token mồi
[Start]rồi chạy chúng qua decoder để lấy được từTôi. - Thêm từ
Tôivào token mồi để có[Start] Tôi. - Lại kết hợp encoded representation và
[Start] Tôirồi chạy chúng qua encoder để lấy tiếp từcó. - Lặp lại 2 bước trên cho đến khi ta gặp từ
[End]. Nếu mọi việc suôn sẻ ta sẽ nhận được câu[Start] Tôi có một giấc mơ [End]. - Lược bỏ token mồi và token kết thúc để thu được kết quả cuối cùng:
Tôi có một giấc mơ.
Mối liên hệ giữa machine translation và bài toán hôm nay
Sau khi tìm hiểu về cách hoạt động của Transformer trong machine translation, tôi nảy ra một ý tưởng. Ta có thể coi Tiếng Việt không dấu là một ngôn ngữ mới và tìm cách dịch ngược nó về Tiếng Việt có dấu. Khi so sánh với một bài toán machine translation thông thường, ta có một số lợi thế lớn.
- Việc chuyển từ Tiếng Việt có dấu sang Tiếng Việt không dấu là rất dễ dàng. Vì thế ta có thể nhanh chóng tạo training data từ file văn bản.
- Một đoạn văn có dấu và một đoạn văn không dấu luôn luôn có cùng số từ. Vì thế ta không cần tới token kết thúc; ta chỉ cần token mồi mà thôi.
- Một từ không dấu chỉ tương ứng với một vài từ có dấu nhất định. Ví dụ,
machỉ có thể là một trong các từma/mà/mả/mã/má/mạ. Hy vọng là model của ta sẽ học được quy luật đó từ dữ liệu.
Dựa vào các điều trên, tôi tin rằng việc dịch từ Tiếng Việt không dấu sang Tiếng Việt có dấu sẽ đạt được độ chính xác cao hơn các bài toán machine translation thông thường.
Chuẩn bị dữ liệu
Ta sẽ sử dụng dataset Old Newspapers từ Kaggle trong bài hôm nay. Nó có khoảng 16 triệu câu, nhưng chỉ có tầm 720,000 câu Tiếng Việt. Dataset này được lưu trong một file tsv và nặng gần 6 GB. Tôi viết ứng dụng này để đọc toàn bộ file, lọc ra các câu Tiếng Việt, và lưu chúng cùng bản không dấu ra một file riêng. Tôi gọi ứng dụng đó là VietnameseCrawler.
Ta có thể chạy ứng dụng từ command line.
dotnet run <đường dẫn tới file đầu vào> <đường dẫn tới file đầu ra>
Dưới đây là một vài dòng trong file đầu ra.
cac nhac sy do deu dang duoc vinh danh ca -> các nhạc sỹ đó đều đáng được vinh danh cả
cai ma ngay nay cho nao cung thieu -> cái mà ngày nay chỗ nào cũng thiếu
gia ve dao dong tu 78 den 158 usd -> giá vé dao động từ 78 đến 158 usd
khong cho phep tre em duoi 4 tuoi -> không cho phép trẻ em dưới 4 tuổi
Train thử một model đơn giản
Bước preprocessing
Như thường lệ, code để train model được viết bằng Python và sử dụng framework Keras. Đầu tiên, ta đọc dữ liệu từ file, rồi chia nó thành tập training, tập validation, và tập test.
from data_loader import load_data
file_path = 'dataset/old-newspaper-vietnamese.txt'
train_pairs, val_pairs, test_pairs = load_data(file_path, limit=10000)
Chú ý là ta chỉ đọc 10,000 câu đầu tiên từ file. Đó là vì ta muốn chạy một số thử nghiệm trước khi train model trên toàn bộ dữ liệu.
Ta tạo source vectorization và target vectorization từ tập training. Những vectorization này được dùng để chuyển dữ liệu từ dạng text sang tensor, nhờ thế ta có thể train model deep learning bằng các tensor đó. Đừng quên lưu lại các vectorization.
from data_loader import load_data, save_vectorization
source_vectorization, target_vectorization = create_vectorizations(train_pairs)
save_vectorization(source_vectorization, 'result/source_vectorization_layer.pkl')
save_vectorization(target_vectorization, 'result/target_vectorization_layer.pkl')
Bước tiếp theo là chuyển dataset của ta từ dạng text sang tf.data.Dataset. Ta sẽ có từng tf.data.Dataset riêng biệt cho tập training, tập validation, và tập test.
from data_loader import make_dataset
batch_size = 64
train_ds = make_dataset(train_pairs, source_vectorization, target_vectorization, batch_size)
val_ds = make_dataset(val_pairs, source_vectorization, target_vectorization, batch_size)
test_ds = make_dataset(test_pairs, source_vectorization, target_vectorization, batch_size) # Ta dùng object này trong bước đánh giá
Dùng lớp TransformerModel để train model
Ta dùng lớp TransformerModel để train model. Đầu tiên, ta sẽ sử dụng các thiết lập mặc định là 256 dimension trong layer embed, 2048 dimension trong layer Dense, 8 attention head, và dropout với tỷ lệ là 0.5.
from transformer_model import TransformerModel
transformer = TransformerModel(source_vectorization=source_vectorization,
target_vectorization=target_vectorization)
Sau các bước trên, ta có thể khởi tạo model và bắt đầu train. Ta sẽ train model trong 50 epoch và chỉ giữ lại phiên bản với validation accuracy cao nhất.
transformer.build_model(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
transformer.fit(train_ds, epochs=50, validation_data=val_ds,
callbacks=[
tf.keras.callbacks.ModelCheckpoint(
filepath='result/restore_diacritic.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
Kết quả đầu tiên
Vì ta chỉ dùng 10,000 câu để train model nên thời gian train là tương đối nhanh. Với GPU yếu như của tôi, train 50 epoch sẽ tốn tầm 30 phút. Tuy nhiên, test accuracy và test loss cũng không được cao lắm. Ta chỉ đạt được test loss là 0.6837 và test accuracy là 69.13%. Có nghĩa là model của ta chỉ đoán đúng token tiếp theo với xác suất là 69.13%.
transformer.evaluate(test_ds) # Sẽ in ra [0.6836796998977661, 0.691321611404419]
Hãy xem thử giá trị loss/accuracy tại từng epoch.
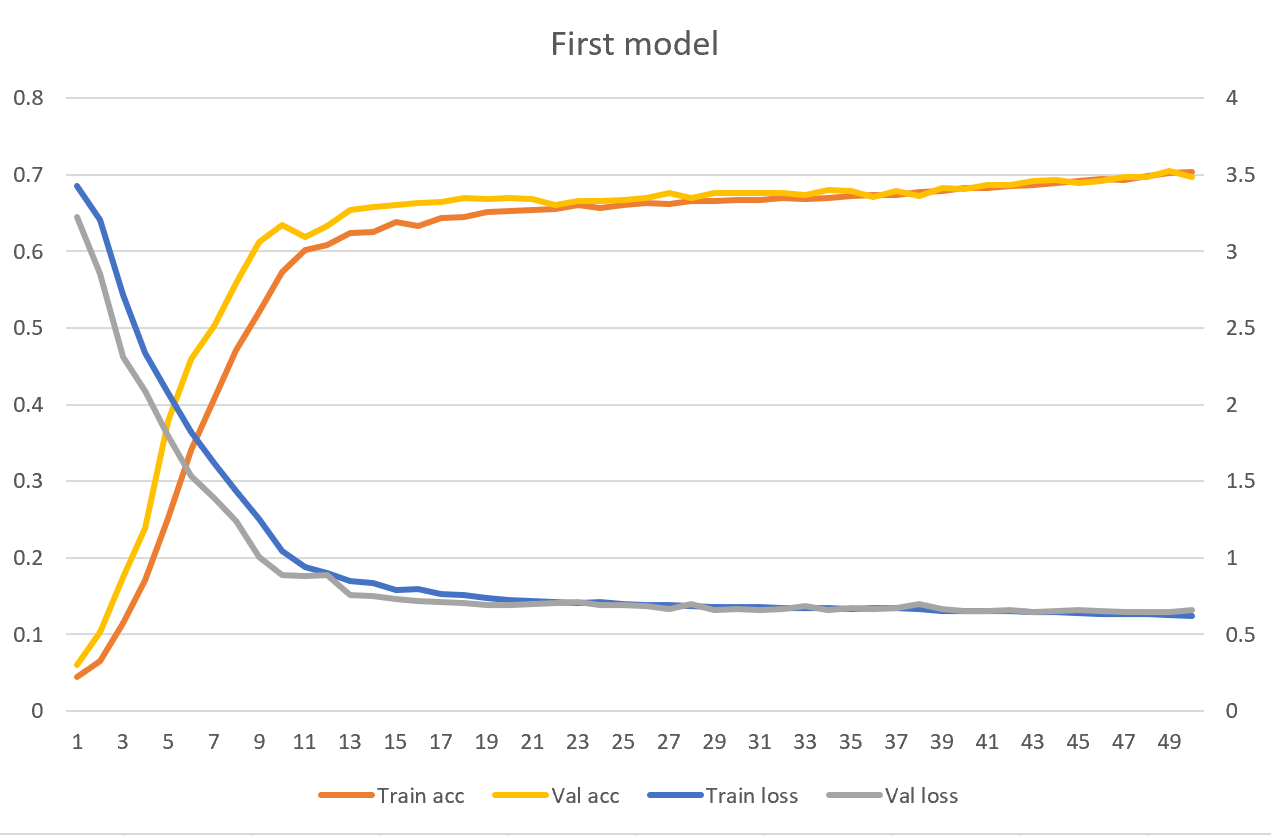
Có thể thấy rằng validation loss/accuracy là xấp xỉ training loss/accuracy. Có nghĩa là model của ta vẫn đang underfitting. Thiết lập mặc định không có đủ capacity để thực hiện dịch.
Tăng capacity cho model
Có một số cách để tăng capacity cho model. Ta có thể tăng số dimension trong layer embed và layer Dense của Transformer, tăng số attention head, và giảm tỷ lệ dropout. Nhưng tiếc là thiết lập mặc định cũng đã gần quá sức với GPU của tôi. Tôi không thể tăng số dimension của layer embed lên quá 256. Và 16 attention head là giới hạn tối đa mà tôi có thể dùng nếu không muốn GPU bị lỗi hết bộ nhớ.
Tiếp theo, ta sẽ train 2 model bằng 300,000 câu và dùng các thiết lập dưới đây.
- Thiết lập 1: 8.192 dimension trong layer Dense của Transformer, 8 attention head, dropout với tỷ lệ là 0.2.
- Thiết lập 2: 2.048 dimension trong layer Dense của Transformer, 16 attention head, dropout với tỷ lệ là 0.2.
Kết quả thu được như sau.
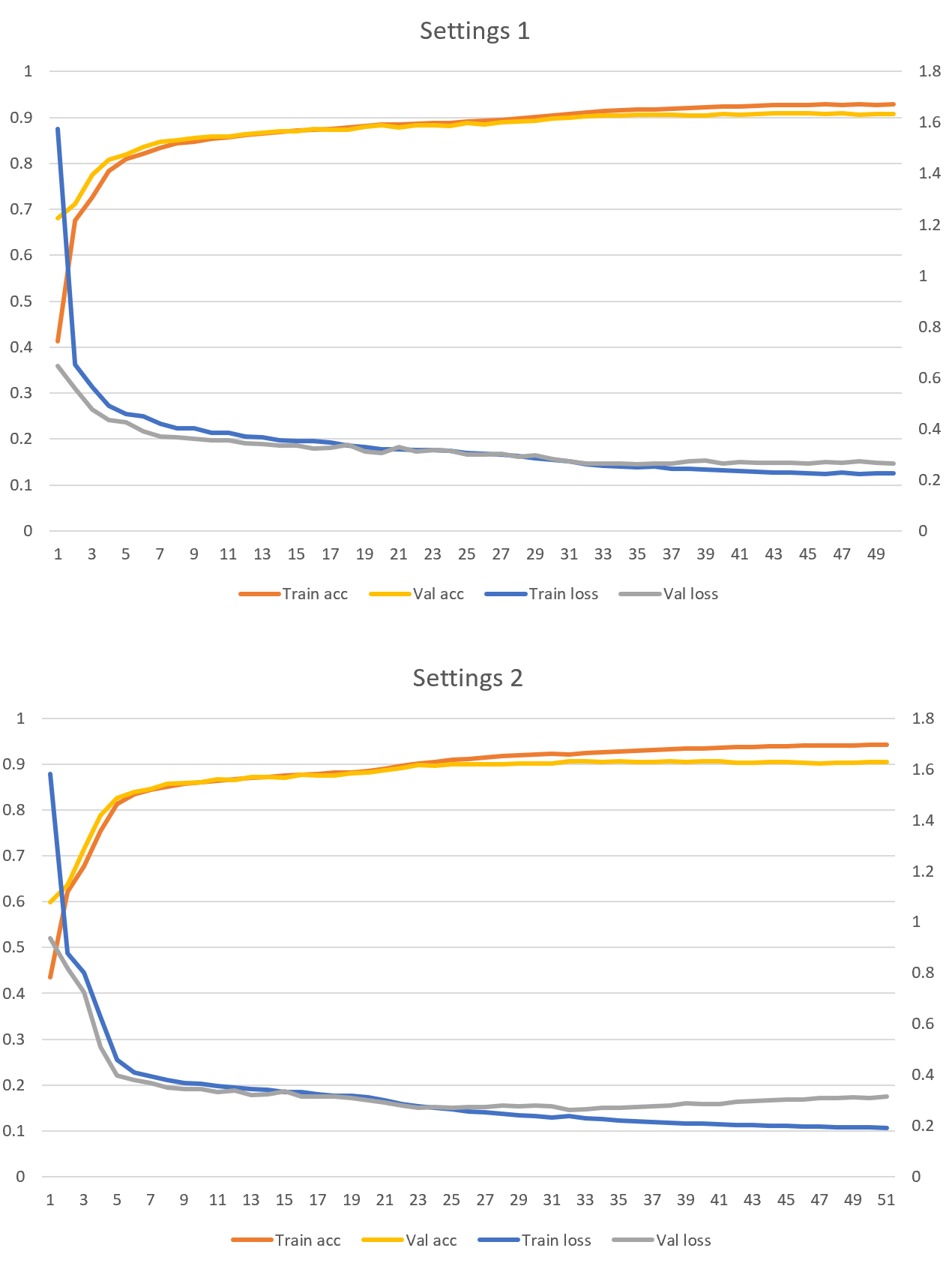
Ta đã đạt được validation accuracy là 90%. Đây là điều dễ hiểu, vì ta dùng nhiều dữ liệu để train model. Cả 2 thiết lập ở trên đều có accuracy xấp xỉ nhau, nhưng Thiết lập 1 chạy nhanh hơn 20% trên GPU của tôi. Hơn nữa, tôi chưa thấy dấu hiệu của overfitting trong cả 2 trường hợp trên.
Train model bằng toàn bộ dữ liệu
Từ kết quả trên, ta sẽ dùng Thiết lập 1 để train model bằng toàn bộ dữ liệu hiện có. Nhưng lần này ta sẽ bỏ hẳn layer Dropout.
train_pairs, val_pairs, test_pairs = load_data(file_path, limit=None)
# ...lược bỏ bớt một số đoạn code
transformer = TransformerModel(source_vectorization=source_vectorization,
target_vectorization=target_vectorization,
dense_dim=8192, num_heads=8, drop_out=0)
Lần này, bước train model tốn mất hơn 2 ngày, và cho kết quả như dưới đây.
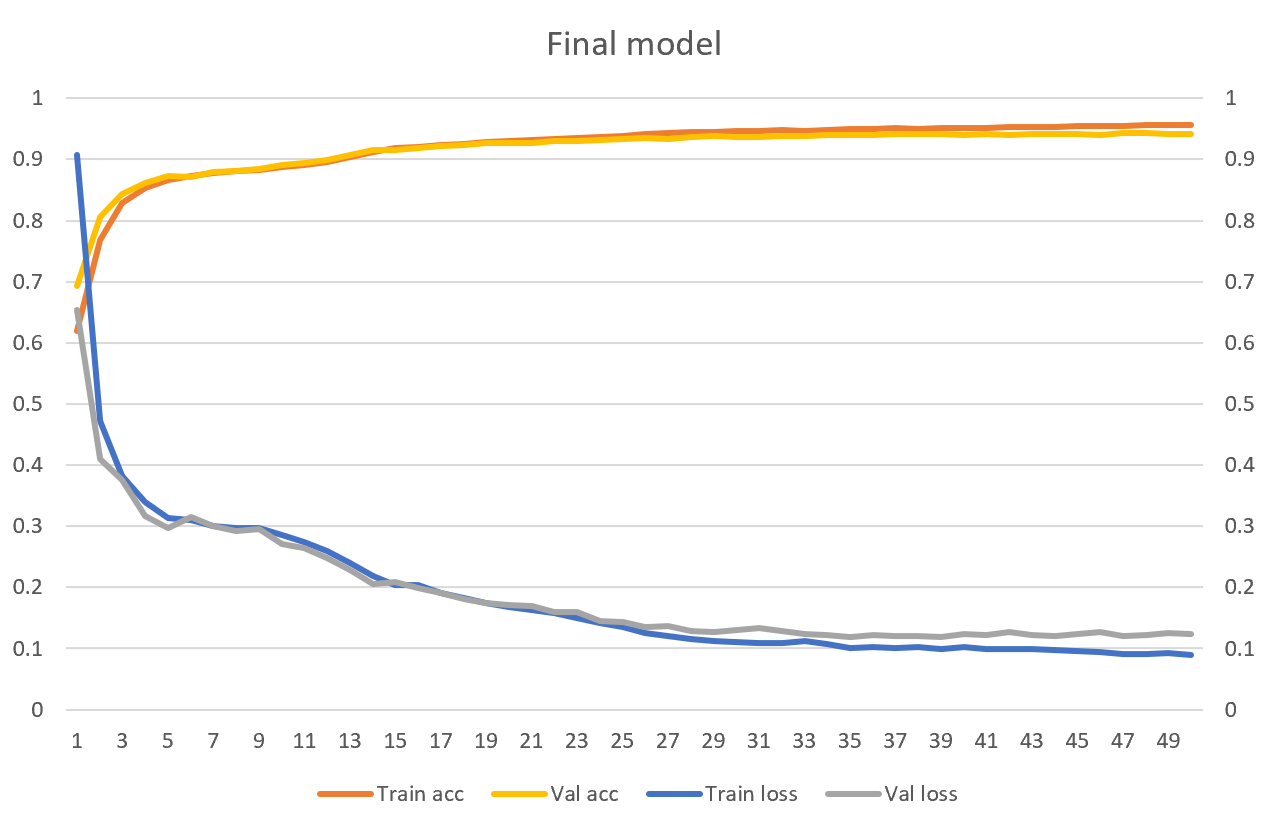
transformer.evaluate(test_ds) # [0.12277301400899887, 0.9405344128608704]
Ta đã đạt được test accuracy là 94.05%. Tôi tin rằng nếu tăng capacity của model lên thì ta còn cải thiện accuracy được hơn nữa. Nhưng tiếc là GPU của tôi đã đạt đến mức giới hạn.
Thêm dấu cho một vài ví dụ
Ta thử chạy một số câu không dấu dưới đây qua model.
texts = [
'co phai em la mua thu ha noi'
'em con nho hay em da quen',
'ha noi mua nay vang nhung con mua',
'dat nuoc toi thon tha giot dan bau'
]
for text in texts:
print(transformer.predict(text))
| Đầu vào | Đầu ra |
|---|---|
| co phai em la mua thu ha noi | có phải em là mùa thu hà nội |
| em con nho hay em da quen | em còn nhớ hay em đã quên |
| ha noi mua nay vang nhung con mua | hà nội mùa này vắng những cơn mưa |
| dat nuoc toi thon tha giot dan bau | đất nước tôi thon thả giọt đàn bầu |
Cách tiếp tục train model sau khi tạm dừng
Như đã nói ở trên, thời gian train model của ta trên toàn bộ dữ liệu là hơn 2 ngày. Vì thế, ta cần phải có cách để tạm dừng rồi tiếp tục quá trình train. Thật may là Keras có hỗ trợ chức năng này.
from data_loader import load_vectorization_from_disk
source_vectorization = load_vectorization_from_disk('<đường dẫn tới file source vectorization>')
target_vectorization = load_vectorization_from_disk('<đường dẫn tới file target vectorization>')
# ...lược bỏ bớt một số đoạn code
transformer = TransformerModel(source_vectorization=source_vectorization,
target_vectorization=target_vectorization,
model_path='<đường dẫn tới model>')
transformer.fit(train_ds, epochs=50, validation_data=val_ds,
callbacks=[
tf.keras.callbacks.ModelCheckpoint(
filepath='result/restore_diacritic.keras',
save_best_only='True',
monitor='val_accuracy'
)
])
Kết thúc
Thêm dấu cho Tiếng Việt không dấu là một vấn đề thú vị với nhiều ứng dụng trong thực tế. Tôi tìm được bài báo khoa học này của nhóm nghiên cứu trường ĐHBKHN (các bạn cùng lớp có thể vẫn nhớ cô Trang, cô dạy môn Lập trình hướng đối tượng hồi năm thứ 3). Nhóm nghiên cứu dùng Transfomer kết hợp với một vài phương pháp khác để thêm dấu cho từng chữ cái (thay vì thêm dấu cả từ như trong bài hôm nay). Phương pháp đó có độ chính xác là 98.37%, nhưng cần lượng dữ liệu lớn gấp 15 lần, đồng thời cần dùng tới GPU Tesla V100 PCIe để train model trong 5 ngày.
Giá mà tôi cũng có card Tesla V100:). Nếu tăng capacity của model hơn nữa và train trên một tập dữ liệu lớn hơn thì biết đâu tôi cũng sẽ đạt được độ chính xác tương tự. Tuy nhiên, tôi nghĩ là với một project làm cho vui thì test accuracy đạt tới 94.05% cũng không phải là tồi.
One Thought on “Thêm dấu cho Tiếng Việt bằng Transformer”