Note: see the link below for the English version of this article.
https://duongnt.com/fast-feature-extraction
Trong bài trước, chúng ta đã train một convolution network để đoán giới tính qua ảnh. Hôm nay, chúng ta sẽ áp dụng fast feature extraction để tăng tốc độ train, đồng thời cải thiện độ chính xác của model.
Các bạn có thể tải toàn bộ code ví dụ trong bài từ link dưới đây.
https://github.com/duongntbk/fast_feature_extraction_demo
Tổng quan về fast feature extraction
Hạn chế của convolution network
Model mà ta train được trong bài trước có 2 nhược điểm.
Nhược điểm thứ nhất là convolution network rất nặng. Mặc dù trong bài trước ta chỉ dùng một model đơn giản, GPU của tôi vẫn cần đến 6 giây để train mỗi epoch. Khi tôi thử train model bằng CPU thì còn tốn thời gian hơn nhiều.
Nhược điểm thứ hai là vì ta có ít training data, độ chính xác của model trên test data chỉ đạt được đến 91%. Nếu ta tăng capacity của model thì model sẽ chỉ ghi nhớ tất cả dữ liệu trong training data. Điều này sẽ dẫn tới overfitting; tức là training loss và training accuracy vẫn được cải thiện nhưng validation loss và validation accuracy thì dậm chân tại chỗ.
Giới thiệu fast feature extraction
Trước hết ta sẽ điểm lại 2 lý do vì sao convolution network lại phù hợp cho các bài toán xử lý ảnh.
- Kiến trúc này có tính phân lớp. Những layer ở mức thấp sẽ học những cấu trúc đơn giản trong ảnh, ví dụ như đường thẳng hay đường cong. Còn các layer ở mức cao sẽ học những cấu trúc tổng quan hơn, cấu thành từ những cấu trúc học được trong layer mức thấp. Điều này là phù hợp với bản chất của ảnh (các chi tiết lớn được cấu thành từ chi tiết nhỏ).
- Sau khi đã học được một cấu trúc ở trong một phần của ảnh, convolution network có thể áp dụng cấu trúc đó vào phần khác của ảnh. Tức là convolution network có khả năng khái quát hóa từ dữ liệu đã học.
Vì thế, nếu ta train một convnet trên bộ dữ liệu đủ lớn, những layer ở mức thấp của nó sẽ học được những cấu trúc với đủ tính tổng quan, có thể được áp dụng vào các bài toán xử lý ảnh khác. Đây là cơ sở của fast feature extraction. Dưới đây là các bước để train model với fast feature extraction.
- Chạy training data qua các layer ở mức thấp của một convnet đã được train sẵn. Bước này sẽ giúp ta trích xuất được các feature từ ảnh (extract feature).
- Train một model trên những feature đã trích xuất được. Lúc này, model mới của ta không cần có capacity cao.
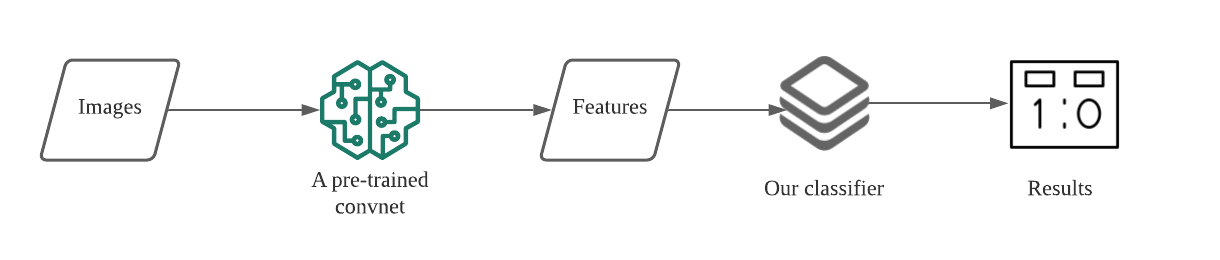
Fast feature extraction có những lợi thế như sau.
- Vì model lúc này không cần capacity cao và ta đã thực hiện bước trích xuất feature từ trước, quá trình train model sẽ rất nhanh.
- Vì ta train model trên feature được trích xuất bởi 1 model mạnh, độ chính xác của model của ta cũng sẽ được cải thiện.
Tất nhiên cái gì cũng có giá của nó. Fast feature extraction cũng có một số nhược điểm như sau.
- Vì tất cả training data đã được chạy qua một convnet từ trước nên ta không thể thực hiện data augmentation.
- Khi dùng model để thực hiện dự đoán, đầu tiên ta phải cho dữ liệu chạy qua convnet. Điều này làm việc sử dụng model trở nên phức tạp hơn.
Convnet được train sẵn mà ta sử dụng
Ta sẽ dùng VGG19 để thực hiện trích xuất feature. Model này được train trên bộ dữ liệu ImageNet. Bộ dữ liệu này bao gồm hàng triệu ảnh với hàng ngàn nhãn khác nhau. Vì thế ta có thể hy vọng là VGG19 đã học được những cấu trúc đủ tính tổng quan.
Keras giúp cho việc sử dụng VGG19 trở nên dễ dàng hơn. Ta có thể tải nó bằng code dưới đây.
from tensorflow.keras.applications import VGG19
vgg19_base = VGG19(
include_top=False, # Ta sẽ thay classifier gốc bằng classifier mới của ta
weights='imagenet', # Tải giá trị parameter học được từ ImageNet
input_shape=(150,150,3))
Chú ý là ta không sử dụng những layer trên cùng của VGG19. Nguyên nhân vì ta sẽ tự train một classifier mới, phù hợp hơn với bài toán của mình.
Sử dụng fast feature extraction để train lại model
Chuẩn bị training data
Giống như trong bài trước, ta sẽ dùng bộ dữ liệu khuôn mặt từ link này. Bước đầu tiên là trích xuất feature từ tất cả các ảnh trong training data. Ta sẽ lưu feature sau trích xuất bằng định dạng HDF5. Xin xem bài này để đọc thêm về cách dùng HDF5 với Python.
from image_to_hdf5 import write_data_to_hdf5
write_data_to_hdf5('dataset/train', 'hdf5_data/train.hdf5')
write_data_to_hdf5('dataset/valid', 'hdf5_data/valid.hdf5')
write_data_to_hdf5('dataset/test', 'hdf5_data/test.hdf5')
Cần chú ý một số điểm sau trong hàm write_data_to_hdf5.
image = load_img(data_paths[i], target_size=(150, 150), interpolation='bilinear') # Đọc dữ liệu ảnh từ đĩa
image = img_to_array(image, data_format='channels_last') # Chuyển dữ liệu ảnh sang tensor
image = preprocess_input(image).reshape(1, 150, 150, 3) # Chuyển tensor ảnh sang dạng mà VGG19 sử dụng
features = vgg19_base.predict(image).reshape(4*4*512) # Xử lý này tương tự với xử lý của layer Flatten
writer.write(features, labels[i]) # Ghi feature đã được trích xuất vào file HDF5
Tối ưu hyperparameter với KerasTuner
Feature sau khi được trích xuất sẽ có shape là (None, 8192). Ta sẽ chạy nó qua một classifier cấu thành từ một số layer Dense.
Cũng giống như trong bài trước, ta sẽ dùng KerasTuner để tìm ra tổ hợp hyperparameter tốt nhất. Đây là lớp hyper model của ta. Ở đây ta sử dụng một hàm mới là hp.conditional_scope. Hàm này giúp đảm bảo là ta chỉ sử dụng 3 Dense layer nếu số unit trong Dense layer thứ nhất là 32 hoặc 64.
if first_dense in [32, 64]:
with hp.conditional_scope('first_dense', [32, 64]):
if hp.Boolean('extra_dense_layer'):
with hp.conditional_scope('conditional_scope', [True]):
dense = layers.Dense(hp.Choice('extra_dense', [4, 8, 16]), activation='relu')(dense)
Ta test mỗi tổ hợp trong 50 epoch và chạy mỗi test 2 lần. Sau 160 test, ta tìm ra được tổ hợp tốt nhất là như dưới đây.
Hyperparameter |Best Value So Far
first_dense |64
dropout_rate |0.5
extra_dense_layer |False
extra_dense |None
Nó tương ứng với kiến trúc sau.
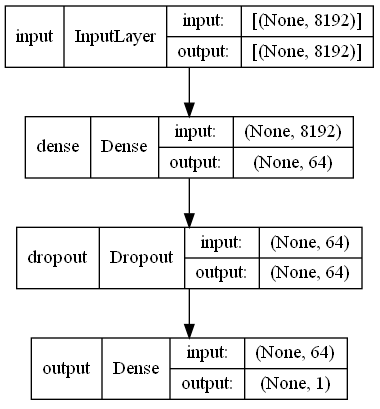
Dưới đây là test loss và test accuracy.
[0.6207340359687805, 0.9470587968826294]
Vì kiến trúc mới rất đơn giản nên ta đã giảm được thời gian train model đi nhiều. Trên máy của tôi, thời gian train convnet trong bài trước là 6 giây cho mỗi epoch; với fast feature extraction, giờ đây mỗi epoch chỉ còn tốn 300 mili giây. Tốc độ train model đã được cải thiện 20 lần, thậm chí tôi còn có thể train model mới chỉ với CPU. Hơn thế nữa, ta còn cải thiện được test accuracy thêm 4% so với bài trước. Các bạn có thể tải model mới từ đường link này.
Sử dụng model mới để thực hiện dự đoán
Để minh họa, ta sẽ thử chạy một bức ảnh của tôi qua model mới.

from tensorflow.keras.applications import VGG19
from tensorflow.keras.applications.vgg19 import preprocess_input
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import img_to_array, load_img
model_path = 'gender_prediction_ffe_best.keras'
image_path = 'fast-feature-extraction-example.jpg'
# Đọc ảnh từ đĩa
image = load_img(image_path, target_size=(150, 150), interpolation='bilinear')
image = img_to_array(image, data_format='channels_last')
image = preprocess_input(image).reshape(1, 150, 150, 3)
# Trích xuất feature với VGG19
vgg19_base = VGG19(include_top=False, weights='imagenet', input_shape=(150,150,3))
features = vgg19_base.predict(image).reshape(1, 4*4*512)
# Thực hiện dự đoán
model = load_model(model_path)
result = model.predict(features)
print(result)
Kết quả là như sau.
[0.0000000000000013521977]
Vì model của ta đánh nhãn 0 cho nam và 1 cho nữ nên kết quả trên nghĩa là model dự đoán ảnh này là nam với độ chắc chắn là 99.99999999999986478023%. Tôi tin là model này dự đoán đúng :).
Kết thúc
Fast feature extraction giúp ta đẩy nhanh tốc độ train model và cải thiện độ chính xác. Nhưng nó cũng khiến ta phải thực hiện nhiều bước tiền xử lý hơn, đồng thời làm quá trình sử dụng model trở nên phức tạp hơn. Nếu hệ thống của ta không có GPU thì có lẽ đây là một giải pháp phù hợp.
One Thought on “Dùng fast feature extraction để tăng tốc độ train model”